Rate Limiting

Hunter Fernandes
Software Engineer
Our continuous integration provider is CircleCI — we love them! Every time an engineer merges code, several builds get kicked off. Among these is a comprehensive suite of end-to-end tests that run against a shadow cluster.
We call this shadow-cluster testing environment simply “CICD” (Continuous Integration/Continuous Deployment; we’re bad at naming). Its primary purpose in life is to fail when problematic code gets released. CICD dies early so that prod doesn’t later on. There are other niceties from having it, but lighting on fire before prod is one of the more valuable aspects.
A Bad Day
One day a few weeks ago, alerts started firing and our CICD site was slow. Ouch. What gives?
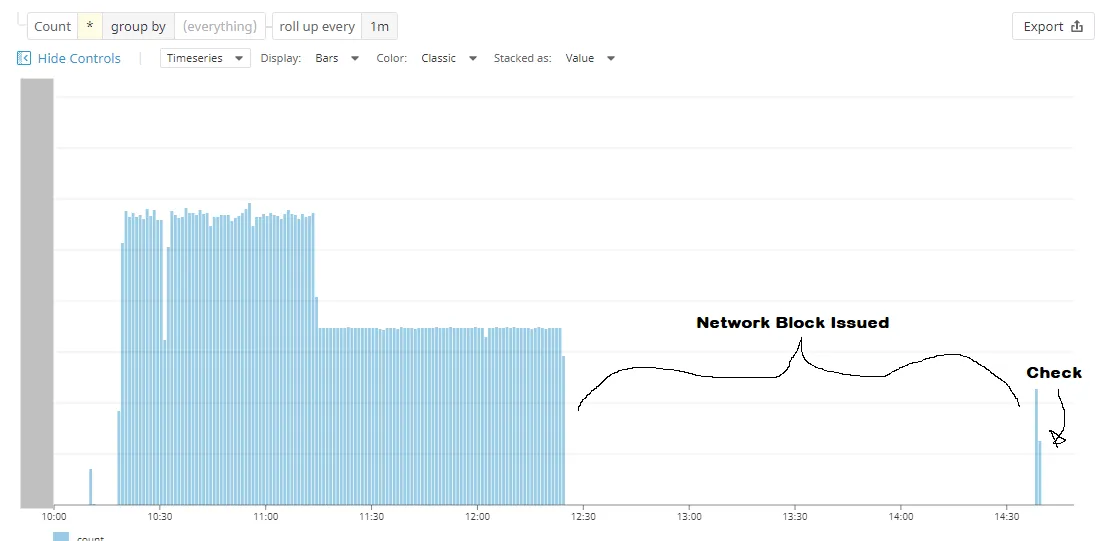
It seems that CircleCI was repeatedly running a test exercising an especially expensive API. Normally, we’d expect this endpoint to be called in short, small bursts. Now, however, it was being called constantly from a single IP address.
Side note: you really should not be doing a large amount of work while handling a request. Doing so exposes yourself to denial-of-service vectors.
CircleCI was very responsive and confirmed that one of their machines had entered an error state. As it turns out, the expensive job was one of the first tasks executed by a worker shard (before the task was promptly killed and run again, ad nauseam).
To immediately restore service to the rest of our engineering team, we black-holed traffic from this IP address via AWS Network Access Control List rules.
This incident, while manageable and only affecting our CICD environment, led us to consider how to block problematic requests in the future.
Requirements
We have a few interrelated goals for our rate limiting:
-
Prevent a single entity from DOSing our API. We are explicitly not attempting to counter a coordinated malicious user with rate limiting. A sufficiently-motivated attacker could use many thousands of IP addresses. For complex attacks, we have tools like AWS WAF. It’s more of a sledgehammer when we’re looking for a scalpel. But when under attack, we can flip WAF on.
-
Enforce baseline usage. Rate limiting gives us another gauge and lever of control over our client software. My firm belief about software is that, if left unchecked, it grows unruly and underpeformant naturally. It’s just a fact of life. (Maybe I am showing my ops colors here).
In order to keep the system snappy for each user, it’s important to limit the calling capacity of all users and force clients to use best-practices. That means, for example, calling batch APIs instead of single-APIs individually one by one.
Within reason, of course. We know ahead of time that in the future, we’ll need to tweak limit thresholds as our product grows in features and scope. Here, limitations lead to better individual client performance. We don’t want to put the cart before the horse.
-
Minimal amount of processing for rejected requests. If we reject requests because they are over the rate limit threshold, we want to spend as few resources processing the reject as possible. It’s a throw-away request, after all. Minimizing processing greatly influences where we want to enforce the rate limit in our request-response infrastructure.
-
Rate limiting the user, not the IP address. A significant number of our customers are large health systems. We see many healthcare providers (who use our most computationally-expensive features) connecting from the same IP address. They tend to all be behind a proxy appliance such as Blue Coat “for compliance reasons.”
Side note: these insane proxies/man-in-the-middle boxes like Blue Coat are one of the reasons I don’t think websites/app backends should participate in HTTP public key pinning. There are many other reasons, but this is the first that most backend folks will run into.
We don’t want to give large hospitals the same limit as we would give to a single user.
Therefore, we want to preferentially rate limit based on authenticated user ID. But, if the client is not logged in and all we have is the IP address, then we’ll have to rate limit on that. Still, we’d prefer the authenticated user ID!
Infrastructure & Where to Throttle
We considered four locations to enforce a rate limit. We strongly considered changing fundamental parts of our infrastructure to prevent malicious attacks like this in the future.
The candidates were:
- A Cloudfront global rate limit.
- An API Gateway rate limit.
- A Traefik plugin to implement rate limiting.
- Adding rate limiting as Django Middleware.
While Cloudfront offered us the chance of caching certain content (and killing two birds with one stone), we ruled it out because there are technical issues ensuring that clients cannot connect directly to our backend instead of solely through CF. The solution would involve custom header values and… it’s all around very hacky.
We ruled API Gateway out because we did not want to restrict ourselves to the 10MB POST payload size limitation. We accept CCDAs and process them. They can get very large — sometimes over a hundred MB. In the future, we’ll move this to direct client-to-S3 uploads, but that is out of the scope of this post.
Traefik has a built-in rate limiting mechanism, but it only works on IP addresses and we have the requirement to throttle based on user ID if it’s available. Hopefully, Traefik will add support for custom plugins soon. They’ve slated it for Traefik 2.
So we are left with implementing our own logic in Django Middleware. This is the worst option in one important way: the client connection has to make it all the way into our Gunicorn process before we can accept/reject the request for being over quota. Ouch.
We really want to protect the Gunicorn processes as much as possible. We can handle as many requests in parallel as we have Gunicorn processes. If a process is stuck doing rate limiting, it won’t be processing another request. If many requests are coming in from a client who is spamming us, we don’t want all of our Gunicorn processes dealing with those. This is an important DOS vector.
Unfortunately for us, Django Middleware is the best we’re going to be able to do for now. So that’s where we’re going to put our code!
Algorithm for Rate Limiting
There are many, many algorithms for rate limiting. There’s leaky bucket, token bucket, and sliding window, to name a few.
We want simplicity for our clients. Ideally, our clients should not have to think about rate limiting or slowing down their code to a certain point. For one-off script runs, we’d like just to accept the load. We want programming against our API to be as simple as possible for our customers. The net effect of this is that we’re looking for an algorithm that gives us high burst capacity. Yes, this means the load is spikier and compressible into a narrower timeframe, but the simplicity is worth it
After considering our options, we went with the fixed-window rate limiting algorithm.
The way fixed-widow works is that you break time up into… uh… fixed windows. For us, we chose 5 minute periods. For example, a period starts at the top of the hour and ends 5 minutes into the hour.
Then, for every request that happens in that period, we increment a counter. If the counter is over our rate limit threshold, we reject the request.
A drawback of the fixed window algorithm is that the user can spend about 2x the limit. And they can spend 2x as fast as they want if they do it at the period boundary. You could offset boundaries based on user ID/IP hashes to amortize this risk… but I think it’s too low to consider at this time.
Implementation
This “shared counter” idea maps nicely to our “microservices with a shared Redis cache” architecture.
Implementing the algorithm is simple! At the start of each request, we run a single command against Redis:
INCR ratelimit/{userid|ip}/2019-01-01_1220
Redis, as an entirely in-memory store, does this super fast. The network latency within an availability zone is several orders of magnitude more than the time it takes Redis to parse this statement and increment this integer. This is highly scalable and is an extremely low-cost to perform rate limiting. We can even shard on user-id/IP when it comes time to scale out.
INCR returns the now-incremented number, and our code verifies this is below the rate limit threshold. If it’s
above the limit, we reject the request.
There are key expiration considerations:
- The effect of this happening in the short term to an active key for an active period would be the user getting more requests then we’d usually give them. Whatever. That’s acceptable for us. We’re not billing per-request. We don’t need to ensure that we have a perfectly accurate count.
- In the long term, the key will stick around indefinitely until it’s evicted at Redis’ leasure (when Redis needs to reclaim memory). We don’t have a durability requirement and, in fact, we want it to go away after we’re done with it.
So INCR by itself is a fine solution. However, you can also pipeline an EXPIREAT if you want to guarantee that the key is removed after the period has expired.
Picking a Threshold
To choose our specific rate limit threshold, we scanned a month’s worth of logs. We applied different theoretically thresholds to see how many requests and users we’d affect.
We want to find a threshold where we affected a sufficiently low:
- Number of unique users.
- Number of unique user-periods.
These are different. For example, consider the following:
If we had 100 users in a month with 99 of them behaving well and sparsely calling us thrice a day while the last user constantly hammered us, we’d calculate that 1% of users affected and 97% of user-periods affected. Threshold-violating users inherently generate more user-periods than normal users.
So our guiding metric is the number of unique users affected. We’ll also pay attention to the number of affected user-periods, but only as supplementary information.
We ended up choosing a threshold that affects less than 0.1% (p99.9) of users and less than 0.01% (p99.99) of user-periods. It sits at approximately three times our peak usage.
Client Visibility
While our clients should not have to fret about the rate limit, the software we write still needs to be aware that it exists. Errors happen. Our software needs to know how to handle them.
Therefore, in every API response, we return the following API headers to inform the client of their rate limiting quota usage:
X-Ratelimit-Limit— The maximum number of requests that the client can perform in a period. This is customizable per user.X-Ratelimit-Used— How many requests the client has consumed.X-Ratelimit-Remaining— How many more requests the client can perform in the current period.X-Ratelimit-Reset— The time in UTC that the next period resets. Really, this is just when the next period starts.
Additionally, when we reject a request for being over the rate limiting threshold, we return
HTTP 429 Too Many Requests.
This makes the error handling logic very simple:
if response.status_code == 429:
reset_time = int(response['X-Ratelimit-Reset'])
time.sleep(max(reset_time - now(), 0))
retry()
Closing Ops Work
And of course, I always include operations dials that can be turned and escape hatches that we can climb through in an emergency. We also added:
-
The ability to modify the global threshold at runtime (or disable it entirely) without requiring a process restart. We stick global configuration into Redis for clients to periodically refresh. On the side, we update this from a more durable source of truth.
-
We allow custom quotas per user by optionally attaching a
quotaclaim to the user JWT. Note that this doesn’t work for IP addresses. It’s conceivable that we may add a secondary Redis lookup for per-IP custom quotas. We could also pipeline this operation into our initial RedisINCRand so it would add very little overhead. -
We continuously validate our quota threshold. We have added a stage to our logging pipeline to gather the
MAX(Used)quota over periods. Our target is to ensure that the p99.9 of users are within our default quota. We compute this every day over a 30-day rolling window and pipe this into Datadog. We alert if the number is significantly different from our expectation. This prevents our actual usage of the API from drifting close to our quota limit.
Further Work
Eventually, we’d like to move this into our reverse proxy (Traefik). While Traefik does buffer the headers and body (so we are not exposed to slow client writes/reads) it would be best if our Python application does not need to handle this connection at all.