SQS's Slow Tail Latency

Hunter Fernandes
Software Engineer
- Backend Background
- Latency at the Tail
- What’s in the tail?
- Strategies to Alleviate Dependent Tail Latency
- Dropping the Service
- Changing API Semantics
- Alleviating Service Dependency Tail Latency
- SQS Latency Theories
- Cold-start connections
- Increasing Keep-Alive Times
- Queue Encryption Key Fetching
- SQS Rebalancing at Inflection Points
- AWS Support
- What Now?
- Footnotes
At my company, we use AWS Simple Queue Service (SQS) for a lot of heavy lifting. We send ✨many✨ messages. I can say that it’s into the millions per day. Because we call SQS so frequently and instrument everything, we get to see its varied performance under different conditions.
![]()
Backend Background
Our application backend is written in Python using Django and Gunicorn and uses the pre-fork model.1 This means that we always need to have a Gunicorn process available and waiting to pick up a connection when it comes in. If no Gunicorn process is available to receive the connection, it just sits and hangs. This means that we need to optimize on keeping Gunicorn processes free. One of the main ways to do this is to minimize the amount of work a process must perform in order to satisfy any single API request.
But that work still needs to be done, after all. So we have a bunch of separate workers waiting to receive tasks in the background. These background workers process work that takes a long time to complete. We offload all long work from our Gunicorn workers to our background workers. But how do you get the work from your frontend Guncicorn processes to your background worker pool?
The answer is by using a message queue. Your frontend writes (“produces”) jobs to the message queue. The message queue saves it (so you don’t lose work) and then manages the process of routing it to a background worker (the “consumers”). The message queue we use is SQS. We use the wonderful celery project to manage the producer/consumer interface. But the performance characteristics all come from SQS.
To recap, if a Gunicorn API process needs to do any non-negligible amount of work when handling a web request, it will create a task to run in the background and send it to SQS through the sqs:SendMessage AWS API. The net effect is that the long work has been moved off the critical path and into the background. The only work remaining on the critical path is the act of sending the task to the message queue.
So as long as you keep the task-send times low, everything is great. The problem is that sometimes the task-send times are high. You pay the price for this on the critical path.
Latency at the Tail
We care a lot about our API response time: high response times lead to worse user experiences. Nobody wants to click a button in an app and get three seconds of spinners before anything happens. That sucks. It’s bad U/X.
One of the most valuable measures of performance in the real world is tail latency. You might think of it as how your app has performed in the worst cases. You line up all your response times (fastest-to-slowest) and look at the worst offenders. This is very hard to visualize, so we apply one more transformation: we make a histogram. We make response time buckets and count each response time in the bucket. Now we’ve formed a latency distribution diagram.
Quick note for the uninitiated: pX are percentiles. Roughly, this means that pX is the Xth slowest time out of 100 samples. For example, p95 is the 95th slowest. It scales, too: p99.99 is the 9,999th slowest out of 10,000 samples. If you’re more in the world of statistics, you’ll often see it written with subscript such as p95.
You can use your latency distribution diagram to understand at a glance how your application performs. Here’s our sqs:SendMessage latency distribution sampled over the past month. I’ve labeled the high-end of the distribution, which we call the tail.
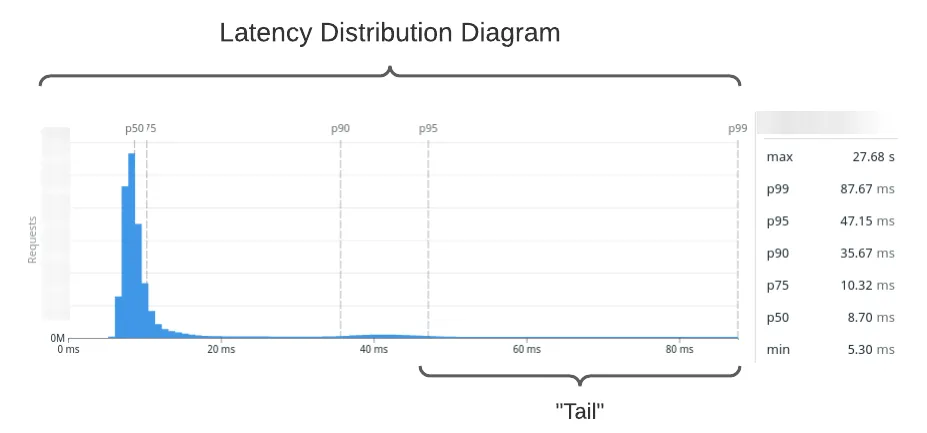
What’s in the tail?
We have a backend-wide meeting twice a month where we go over each endpoint’s performance. We generally aim for responses in less than 100 milliseconds. Some APIs are inherently more expensive, they will take longer, and that’s ok. But the general target is 100ms.
One of the most useful tools for figuring out what’s going on during a request is (distributed) tracing! You may have heard of this under an older and more vague name: “application performance monitoring” (APM). Our vendor of choice for this is Datadog, who provides an excellent tracing product.
For the last several performance meetings, we’ve had the same problem crop up. We look at the slowest 1-3% of calls for a given API endpoint and they always look the same. Here’s a representative sample:
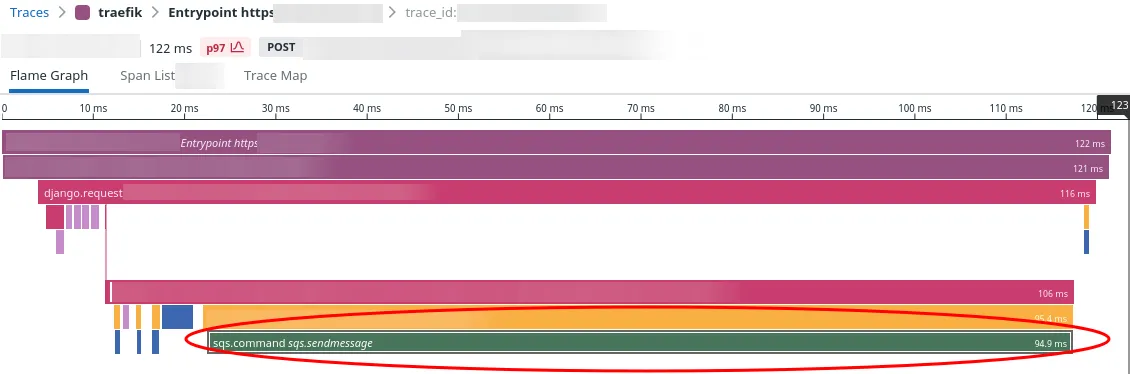
See the big green bar at the bottom? That is all sqs:SendMessage. Of the request’s 122ms response time, 95ms or 75% of the total time was waiting for SQS:SendMessage. This specific sample was the p97 for this API endpoint.
There are two insights we get from this trace:
To improve the performance of this endpoint, we need to focus on SQS. Nothing else really matters.
High tail latency for any of our service dependencies are going to directly drive our API performance at the tail. Of course, this makes total sense. But it’s good to acknowledge it explicitly! It’s futile to try to squeeze better performance out of your own service if a dependency has poor tail latency.
The only way to improve the tail latency is to either drop the poor performer
or to change the semantics of your endpoint. A third option is to attempt to alleviate the tail latencies for your service dependency if you can do so. You can do this if you own the service! But sometimes, all you have is a black box owned by a third party (like SQS).
Strategies to Alleviate Dependent Tail Latency
Dropping the Service
Well, we can’t drop SQS at this time. We’ll evaluate alternatives some time in the future. But for now, we’re married to SQS.
Changing API Semantics
An example of changing API semantics: instead of performing the blocking SendMessage operation on the main API handler thread, you might spin the call out to its own dedicated thread. Then, you might check on the send status before the API request finishes.
The semantic “twist” happens when you consider what happens in the case of a 5, 10, or even 20 second SendMessage call time. What does the API thread do when it’s done handling the API request but the SendMessage operation still hasn’t yet been completed? Do you just… skip waiting for the send to complete and move on? If so, your semantics have changed: you can no longer guarantee that you durably saved the task. Your task may never get run because it never got sent.
For some exceedingly rare endpoints, that’s acceptable behavior. For most, it’s not.
There is yet another point hidden in my example. Instead of just not caring whether the task was sent, say instead we block the API response until the task send completes (off thread). Basically, we get the amount of time we spend doing other non-SQS things shaved off of the SQS time. But we still have to pay for everything over the other useful time. In this case, we’ve only improved perhaps the p80-p95 of our endpoint. But the worst-case p95+ will still stay the same! If our goal in making that change was to reduce the p95+ latency then we would have failed.
Alleviating Service Dependency Tail Latency
SQS has a few knobs we can turn to see if they help with latency. Really, these knobs are other SQS features, but perhaps we can find some correlation to what causes latency spikes and work around them. Furthermore, we can use our knowledge of the transport stack to make a few educated guesses.
Since SQS is a black box to us, this is very much spooky action at a distance.
SQS Latency Theories
So why is SQS slow? Who knows? Well, I guess the AWS team but they aren’t telling.
I’ve tested several hypotheses and none of them give a solid answer for why we sometimes see 5+ second calls.
I’ve documented my testing here for other folks on the internet with the same issue. I’ve looked at:
- Cold-start connections
- Increasing HTTP
Keep-Alivetimes - Queue encryption key fetching
- SQS rebalancing at inflection points
Cold-start connections
How about initiating new connections to the SQS service before keep-alive kicks in on boto3. If our process has never talked to SQS before, it stands to reason that there is some initial cost in establishing a connection to it in terms of TCP setup, TLS handshaking, and perhaps some IAM controls on AWS’ side.
To test this, we ran a test that cold-started an SQS connection, sent the first message, and then sent several messages afterwards when keep-alive was active. Indeed, we found that the p95 of the first SendMessage was 87ms and the p95 of the following 19 calls was 6ms.
It sure seems like cold-starts are the issue. Keep-alive should fix this issue.
A confounding variable is that sometimes we see slow SendMessage calls even in the next 20 operations following an initial message. If the slow call was just the first call, we could probably work around it. But it’s not just the first one.
Increasing Keep-Alive Times
In boto, you can set the maximum amount of time that urllib will keep a connection around without closing it. It should really only affect idle connections, however.
We cranked this up to 1 hour and there was no effect on send times.
Queue Encryption Key Fetching
Our queues are encrypted with AWS KMS keys. Perhaps this adds jitter?
Our testing found KMS queue encryption does not have an effect on SendMessage calls. It did not matter if the data key reuse period was 1 minute or 12 hours.
Enabling encryption increased the p95 of SendMessage by 6ms. From 12ms without encryption to 18ms with encryption. That’s pretty far away from the magic number of 100ms we are looking for.
SQS Rebalancing at Inflection Points
Perhaps some infrastructure process happening behind the scenes when we scale up/down and send more (or fewer) messages throughout the day. If so, we might see performance degradation when we are transitioning along the edges of the scaling step function. Perhaps SQS is rebalancing partitions in the background.
If this were to be the case, then we would see high latency spikes sporadically during certain periods throughout the day. We’d see slow calls happen in bursts. I could not find any evidence of this from our metrics.
Instead, the slow calls are spread out throughout the day. No spikes.
So it’s probably not scaling inflection points.
AWS Support
After testing all of these theories and not getting decent results, we asked AWS Support what the expected SendMessage latency is. They responded:
[The t]ypical latencies for SendMessage, ReceiveMessage, and DeleteMessage API requests are in the tens or low hundreds of milliseconds.
What we consider slow, they consider acceptable by design.
Here’s an output characteristic curve from IRLB8721PbF MOSFET (pdf).
Hardware has such nice spec sheets.
Frankly, I consider this answer kind of a cop-out from AWS. For being a critical service to many projects, the published performance numbers are too vague. I had a brief foray into hardware last year. One of the best aspects of the hardware space is that every component has a very detailed spec sheet. You get characteristic curves for all kinds of conditions. In software, it’s just a crapshoot. Services aiming to underpin your own service should be publishing spec sheets.
Normally, finding out the designed performance characteristics are suboptimal would be the end of the road. We’d start looking at other message queues. But we are tied to SQS right now. We know that the p90 for SendMessage is 40ms so we know latencies lower than 100ms are possible.
What Now?
We don’t have a great solution to increase SQS performance. Our best lead is cold-start connection times. But we have tweaked all the configuration that is available to us and we still do not see improved tail latency.
If we want to improve our endpoint tail latency, we’ll probably have to replace SQS with another message queue.
Footnotes
There are many problems with the pre-fork model. For example: accept4() thundering herd. See Rachel Kroll’s fantastic (and opinionated) post about it. Currently, operational simplicity outweighs the downsides for us. ↩