Software Engineering and Risk Management

Hunter Fernandes
Software Engineer
This is a supplementary blog post to one I coauthored that was posted to our corporate blog: Delivering Better Software, Faster. That blog post came to be because our sales and leadership teams are often questioned on how we are able to move and ship fast without creating unacceptably high risk to our customers. Having lived in DevOps land for years, that question hurts my soul.
My experience is that the healthcare IT industry is a giant, slow, lumbering monstrosity. A slug where the head is, at best, in the early 2010s and the tail is still in the 1980s. Worse, large parts of the industry are struggling with the transformation of healthcare models. The whole thing is broken.

Healthcare IT still uses a lot of faxes. Fax machines have a carve-out in HIPAA and they will be with us forever.
It seems like magic when we show up and offer them a SaaS solution, demonstrate we can ship changes for them in under a week, offload compliance burden, reduce staff toil, and get better patient outcomes. To the captains of these large vessels, heaving to turn and facing their own choppy waters, something that looks like magic is to be questioned as a scam or requiring a hidden tradeoff. Fair enough. One of the frequent takes we hear is some form of: “I interpret your pride in your ability to move fast as actually being indicative of your willingness to cut corners or your negligence in ignoring downstream effects.”
And it’s so… wrong for so many reasons. So we write a customer-facing blog post on the ABCs of our pipeline to assure our customers that the process is safe. We had a more detailed version that got cut down for ― in my own opinion and not representing the views of my company ― being too preachy.
But guess what? This is my blog and I can be preachy. The joke is on them, too: In my capacity as owner of DevOps, I think about the safety of our product and the productivity of our developers literally every single day. So I have opinions.
Moving Fast and Not Breaking Things
In my capacity overseeing DevOps, I have several key areas of responsibility: developer productivity, product security, and availability. Over the past five years, my approach to software engineering has transformed into one of risk management. Contrary to some people’s gut instincts, the tenets of risk management tell us that reducing risk goes hand in hand with maximizing developer productivity and shipping speed.
To understand why, we need to address three things:
- What is risk?
- Why do some people think that moving fast requires a commensurate increase in risk?
- Why does good engineering hygiene cause moving fast to decrease risk?
What is Risk?
The principal risk that engineering ― as an organization ― considers is the risk to our customers and, by extension, our business. We are a strategic technology choice, and our customers depend on us for their ability to do business. We know that reputation is everything and is something that’s difficult to repair once stained. Our goals align with our customers: we protect our reputation with our customers and also protect our customers’ reputation with their patients.
What are our customers worried about? Here’s a handful of issues we think about: that our product will go down and halt their business, that our product will leak data and lead to HIPAA violations, and that our product will be a bad experience for the providers or their patients.
Availability and security are obviously technical concerns in the hands of the engineering team. Many people would say experience is in the hands of product management, but it’s jointly managed with engineering with the addition of an iterative loop, but let’s talk about that later.
A unique thing about risk is that risk is a fractal that unfurls into many upstream risks. Let’s take the example of “product availability” because it’s easy to illustrate. What could lead to product availability risk?
- Product crashes
- Platform instability
- Datacenter outages
Addressing risk requires addressing upstream risks recursively. “Bad code being released” has its own upstream risk contributors. You must recursively manage risk until you are satisfied that each has a countermeasure prepared to alleviate risk to an acceptable degree. Here, risk management relates to other engineering methodologies: this is the flip side of the ubiquitous “five whys.”

Risk satisfaction. Your taste for particular types of risk will vary from organization to organization. For example, I am willing to address the risk of a datacenter going down by going multi-AZ or multi-region. However, I don’t consider it in scope to manage the risk of (to think of an extreme example…) a nuclear exchange destroying every AWS region. This is a clear example, but some tradeoffs are not so clear and have subtle tradeoffs. As always, engineering tradeoff decisions can be more of an art than a science. Finally, it’s worth noting that some organizations do plan to be available after nuclear exchanges and have appropriate contingency plans! Risk tolerance varies!
Myth: Moving Fast = Increasing Risk
Where does the myth of “moving fast requires increased risk” come from? The answer is that it comes from healthcare IT’s perpetual 1980-2010 existence. Healthcare IT is used to the enterprise-software model of owning their own hardware, owning their own deployments, having a multi-year installation and migration headed by a project manager, and having a massive downtime-requiring upgrade every few years. It’s Enterprise Software (capital E capital S). As an institution, that is what they are familiar with and what their instinct tells them to reach for. They do not understand the hands-off SaaS model. In short, they are stuck behind the curve on how modern software is developed, deployed, and maintained. Again: fair enough. They are not software companies.
That is why healthcare executives are immediately suspicious when you pitch a SaaS model and mention you release to production twice a week. All they know of “healthcare software releases” is what has been reported up the chain to them from IT. Namely, constant calls for maintenance periods and notifications to executives about risks of upgrading their Big Software Package. Healthcare execs are not dumb. Rather, we are presenting them with a fundamentally different technical ecosystem. As if that’s not enough, that’s also underpinning a fundamentally different care approach on the business side. There are a lot of departures from the old Enterprise Software model that healthcare execs have to wrap their head around:
- Modern DevOps methodologies flip the old style of software development on its head. “What’s new is inherently risky.”
- SaaS removes operational burden (and some decision-making!) from IT. They have to trust their vendor to not radically change the product without notice. Additionally, they are used to managing their own known risks. They don’t immediately see the value of us reducing operational complexity if they feel they already have it handled. The upside is discounted and the downside is clear: lack of control.
- No waterfall model release schedule. No two-quarter release testing phase before every deployment. In their old model, the big testing phase surely caught would-be devastating bugs. How can a SaaS vendor perform as-thorough of a test in the two days before release? Surely they must be sacrificing assurance and thereby increasing risk! (Not so!)
- Agile development means we will work hand-in-hand with them to improve our product over time in an iterative loop. Again, this differs from the waterfall model where they will throw a big requirements document at us and we’ll meet back in a few quarters. Rather, the role of the project manager fundamentally changes to an ongoing-cooperative role. MVPs are rolled out quickly behind feature flags and immediately handed over to the customer for testing at their leisure. If you are used to the old model, the first (and only?) thing you hear is “un-QAd code is released to production.”
So, given a familiarity with the downsides and tradeoffs of the old model of on-prem Enterprise Software, hearing an offhand comment about how fast we can ship features would lead you to think we are cutting corners. The only way to get out of that mindset is to deep dive into modern software methodologies, which is not their area of expertise. So here is my crash course in modern software methodologies.
Engineering Hygiene → Speed & Risk Reduction
The principles of software engineering combined with the principles of risk management lead us to a simple opinion on how to execute: pull as much risk possible, as soon as possible. As time goes on, the consequences of risk increase. Therefore, the earlier the risk is experienced, the more likely it is to be caught while the consequences are small.
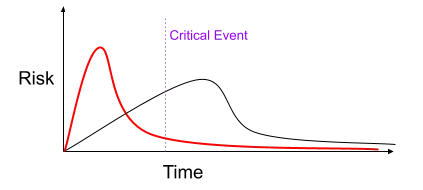
All the investments in tooling, developer experience, and process is intended to move towards the red line’s risk profile. We want to experience as much risk as early as possible so that the long-term “tail” has less risk. This means we catch more bugs earlier, generally before they are released.
Risk management meshes with three other principles of modern software development:
- Releasing early.
- Releasing often.
- Continuously evolving the process.
These three principles synergize together to increase development velocity while decreasing risk. Additionally, we further add specific risk mitigations to each step to fit our risk tolerance.
Release Early
Large waterfall roadmaps don’t work. They are inefficient. The time between handing off the requirements for development and testing the product is too long. That time difference adds risk, lets downstream code ossify, and ultimately increases the cost to get to the final product. Agile development tells us to release a minimum viable product to the customer as fast as possible in order for the customer to influence the development of the product as early as possible.
To further reduce risk, we employ feature flags to keep in-development changes visible only to the customers we are working with. Along with frequent releases and contact with customers, we can experiment and the product can quickly grow in the right direction. This maximizes developer productivity while also getting customers exactly what they want, faster.
Releasing Often
In a nutshell, modern DevOps dogma tells us that breaking up large changes to a system (read: the infrequent Big Software Package Upgrade) into a series of smaller changes leads to faster development velocity and ultimately reduces risk. There are a few reasons for this, but at its simplest, as you approach the tiniest change, the risk approaches zero or is at least confined to a single changed thing. It’s easier to understand how varying a single element affects the overall system rather than many hundreds of varying elements. This is what “release often” means. As the release package size increases, complex interplay arises between the changing components and the state space for what needs to be tested explodes exponentially.
Releasing often also means that there are more opportunities for adjusting things on production. Frequent releases mean that there is no fear of “missing the train” for a release schedule. Don’t worry! The train will be back in two days!
Continuously Evolving the Process
Perhaps the most important aspect of modern software development and DevOps is the obsessive focus on The Process. We routinely scrutinize the entire software development lifecycle for security and speed. Again, pushing as much risk to the front is key. There is a cultural aspect to this as well: when we experience even a minor issue, we always ask two questions:
- How can we immediately fix the issue?
- How can we prevent this from happening in the future?
The second question must be answered with an automated test if at all possible. This prevents the issue from ever occurring in the future: we will commit a test in our code to check for this failure condition early in the process.
The Process is distilled into a multi-step action list in the main blog post, but briefly, the developer loop of our software development lifecycle is:
- Providing a strong baseline developer experience from a “known-good” state.
- Unit tests are required to cover all codepaths, enforced by tooling.
- Code reviews by engineers with competence in the area of the product being changed.
- Staging environment releases that exercise many failure scenarios.
- System / Integration tests that drive all common or critical product usage patterns.
- Manual QA & release approval.
- Feature flags to allow partial releases of product changes to a subset of users.
We have invested in The Process because each step pulls risk forward and catches mistakes early. For the most part, all of this happens fast and automatically through tooling and tests. Code cannot even make it to staging unless it has been linted, tested, and covered. Then even more assurance and de-risking measures run. By the time any code makes it to release, it has been exercised and tested for all potential code paths and has been looked at by multiple pairs of eyes in different ways.
We are largely successful. Releases are very boring affairs. A single engineer reviews a dashboard of green check marks, gets formal product management and engineering approval, and runs yet more tooling that orchestrates release. And voilà, the databases are patched, the code is live and serving real customers! All said and done, a release to production takes about an hour of an engineer’s time. Again, the risk has been moved forward so much that we encounter very few problems by the time we get to production release.
What You Get
We have spent millions of dollars creating and improving The Process because it de-risks quickly and in a fashion that scales up as the number of developers we have grows and our product becomes larger. The risk reduction afforded to us by strong guard rails and our investments in the process allows our developers to move fast and not break things! What we get is a massive boost to developer productivity and confidence in the final product.
In short, risk and developer velocity are both largely functions of engineering hygiene. Increasing velocity does not increase risk. In fact, with proper engineering hygiene, increasing velocity reduces risk due to breaking up risky operations into smaller, more manageable chunks!
So, when DevOps people think of reducing the risk further during stable operations, we prefer hitting the gas instead of the brake. Doing so benefits us from the tailwind of our expensive process investments.