SQS Performance (II)

Hunter Fernandes
Software Engineer
This is a follow-up to my previous blog post, SQS Slow Tail Performance. That post has much more detail about the problem. For various work-related reasons, I am finally revisiting SQS performance. It’s my white whale, and I think about it frequently. And I’ve discovered at least one thing!
HTTP Keep-Alive
In my previous post, I mentioned both that HTTP “cold-start” times and low HTTP Connection: keep-alive times could be a contributing factor. And, after some more investigating, it turns out I was sort of right. Sort of.
HTTP Keep-Alive is when the server indicates to the client that the TCP connection should be kept open after the HTTP Response is sent back. Normally (under HTTP/1), the TCP connection would be closed after the response is completed. Keeping it alive lowers the TCP/TLS overhead associated with making a request. When using keep-alive, you only pay the overhead for the first request and all subsequent requests get to piggyback on the connection.
Persistent connections are so performance-enhancing that the HTTP/1.1 specification makes them the default (§8.1.2.1)! The method by which the server indicates to the client that it wants to close the connection is by sending Connection: close. But the server can just close the connection anyways without warning.
Every 80 Messages
I ran some more tests like last time. Importantly, the difference from the testing I did in my previous post was that I executed more sqs:SendMessage calls serially. Last time I did 20. This time I did 180. It turns out that the magic number is… 🥁🥁🥁 80!
Every 80 messages, we see a definite spike in request time! To be fair, we don’t only see a latency spike on the 81st message, but we always see it every 80.
And what do you know? 1-1/80 = 98.75. This is where our definite 99th percentile latency comes from! So what the heck is happening every 80 messages?
Test Setup
To test sqs:SendMessage latency, I set up an EC2 instance in order to run calls from within a VPC. This should minimize network factors. Typically, we see intra-vpc packet latency of about 40 microseconds (the best of the three largest cloud providers; study courtesy of Cockroach Labs). So any latency we see in our calls to SQS can reasonably be attributed to just SQS and not the network between my test server and SQS servers.
Here are the test parameters:
- Queue encryption enabled with the default AWS-provided key.
- The data key reuse period for encryption was 30 minutes.
- Message expiration of 5 minutes. We’ll never consume any messages and instead, choose to let them expire.
- Visibility timeout of 30 seconds. This should not affect anything as we are not consuming messages.
- Message Payload of 1 kB of random bytes. Random so that it’s not compressible.
- Concurrent runs capped to 16.
I ran 100 runs, each consisting of 180 serial sends each and then aggregated the results. Here are the results, plotting the p75 latency across all the calls at a given position:
.52x-7xx-_Z2bVCX2.webp)
Notice that every 80 messages we see a big bump in the p75 latency? We have high call times on the 1st, 81st, and 161st messages. Very suspicious!
Connection Reuse
The AWS client library I use is boto3, which also returns response headers. As it turns out, SQS is explicitly sending Connection: close to us after 80 messages being sent on a connection. SQS is deliberately closing the connection! You’ll typically see this behavior in distributed systems to prevent too much load from going to one node.
However, we don’t just see slow calls every 80 sends. We see slow calls all over the place, just less frequently. Here is the max() call time from each position.
.CvFAJUyy_ZiQVJh.webp)
This seems like evidence that the connections are being dropped even before the 80th message. Boto3 uses the urllib2 under the hood, and urllib comes with excellent logging. Let’s turn it on and see what’s going on!
import logging
logging.getLogger('urllib3').setLevel(logging.DEBUG)
logger = logging.getLogger()
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
console_handler.setFormatter(logging.Formatter("[%(name)s]: %(message)s"))
logger.addHandler(console_handler)
And, after executing a single serial run we see connection resets exactly where we’d expect them.

Unfortunately, we don’t also see “silently dropped connections” (aka, TCP connections closed without a Connection: close header). urllib2 is indicating that some of the non-80 slowness is still being sent over an established connection. The mystery continues…
SQS VPC Endpoint
There was some question what kind of performance impact VPC Endpoints would have. So I set one up for SQS in my test VPC and the results were… meh. Here’s a histogram of call times and some summary statistics:
.WoXwOfx8_15B10i.webp)
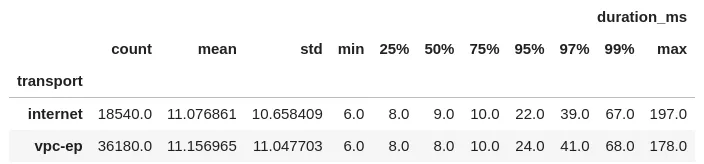
Completely meh. The VPC Endpoints runs are actually worse at the tail. You’d think that eliminating any extra network hops through an Endpoint would reduce that, but 🤷.
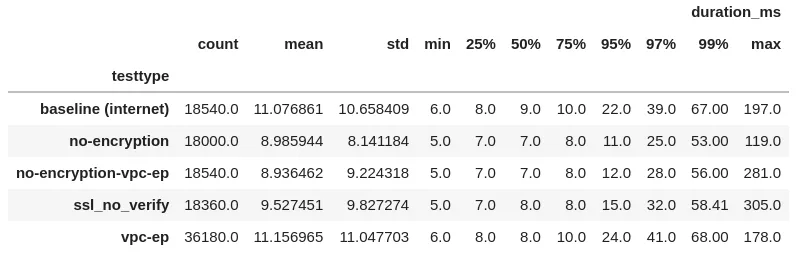
Here are all the test parameters I checked. You can see that the 99% remains pretty high.
Further Work
I think this is the end of the line for SQS performance. We’ve made sure that everything between us and SQS is removed and yet we’re still seeing random spikes of latency that can’t be explained by connection reuse.