Carium
I run infrastructure and platform at Carium, a digital health startup. Healthcare is a complex and highly regulated industry, and that has colored my work in a lot of ways. At Carium, I rose from a Software Engineer to a Staff Engineer. An interesting side effect of successive promotions in a startup is that you wear a lot of hats.
What do I do?
Infrastructure Architecture
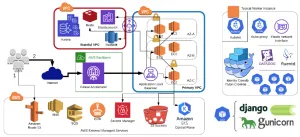
I make a lot of infrastructure architecture diagrams.
All of our AWS infrastructure is my responsibility. From our multi-account setup to our networking, compute machine types, availability zone decisions, security models, load balancers, …all of it. A lot of it is still my creation from the early days of the company. Ultimately, I still oversee all of it.
The triple aim is to ensure our infrastructure is secure, stable, and cost-effective.
I work with the excellent folks in our product team to ensure that our infrastructure is aligned with our product and we can maneuver quickly to meet the needs of our customers. I also work to apply general software engineering principles to our infrastructure. For example, we have a CI/CD pipeline for our infrastructure code and we use Terraform to manage our infrastructure as code. This reduces risk and increases velocity.
This is one of my favorite parts of my job. I love working on infrastructure: the problems are broad and the solutions give a win to the whole product experience. It’s very impactful work.
Platform Stability
As part of owning the architecture, I also own the stability of our platform. Any downtime and scheduled maintenance runs through me, and I oversee outage response and post-mortems.
In support of this, I manage fire drills, incident management processes, runbooks, and our downtime monitoring and alerting.
Additionally, I oversee and orchestrate complex, staged database upgrades and architectures. I am particularly proud of this because it poses a significant risk to the business. I have a good track record of being able to execute these upgrades without any downtime.
Monitoring Stack
I run our metrics and logging stack. We aggregate all logs, enrich them with provenance data, and centralize them into a logging provider. My engineers can search and filter logs to diagnose issues and set up alarms to alert them to issues.
Having a good logging stack is essential to minimizing problem resolution time. We immediately surface stack traces and error messages to our engineers through a Slack channel. Good engineering discipline keeps that channel clean and useful, so that a new stack trace sticks out like a sore thumb.
Publicly surfacing errors is a powerful tool. It’s not about blame. It’s about fixing issues and ensuring the accountability of the engineering team. It’s about improving the product and measuring how “we, the engineering team” are doing.
API Performance

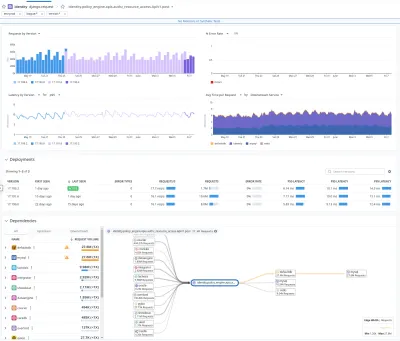
We evaluate API performance monthly.
I run a monthly engineering meeting where we review API and task performance and issue tickets to address any issues. This dovetails with managing our monitoring stack.
As a team, we’ve learned to spot common performance bugs, and we’ve been able to address them before they become a problem. We have seen (and fixed!) all kinds of problems: N+1 queries, bad indexes, bad call patterns, etc.
There are a lot of tricks to this, but the most important one is to have a good monitoring stack and a good relationship with your developers.
Compliance
I run the technical arm of our HIPAA and SOC-2 compliance programs. As a healthcare company, we are subject to a lot of regulations and it takes a few key people from every department to keep us compliant. I help shape our corporate policies, engineering SDLC, technical controls, and audit processes.
Your compliance program can benefit the business and developer velocity if done right. Too many companies see compliance as an “overhead tax” burden that slows the business. On the engineering side, we use compliance to guide our best practices and ensure we are doing the right things. With the right policies and mindset, compliance only burdens bad practices.
The more technical portions of this hat involve overseeing disaster recovery and business continuity planning and liaising with our auditors.
Cost Reporting
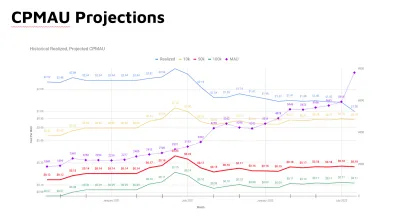
I maintain a financial model that shows our cost-per-user projections. (This data here is fake.)
I am particularly proud of my cost reporting. Every month, I compile a large report that shows per-vendor and per-service cost for our product. I maintain a financial model that shows our cost-per-user projections. Cost-per-user projections at varying scale levels are a key metric for our business. It dictates our margin, which affects our pricing, our growth strategy, and even our fundraising. Of course, those decisions are made at a higher level than me.
Having oversight into cost coupled with infrastructure management and platform stability is a powerful combination. It’s given me much insight into the business and helped me become a better engineer.
Platform Security
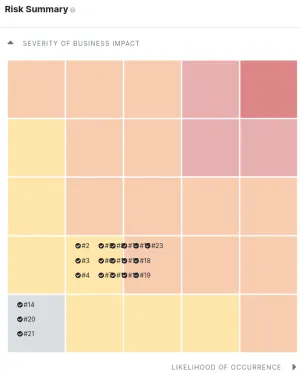
A clean pentest report.
I run our security program. This involves tracking vulnerabilities, running security scans, patching, security architecture, and managing our security posture in general. Infrastructure security & intrusion detection is a big part of this.
Additionally, I run bi-annual pentesting engagements and manage the remediation of any findings.
A synergy between security and engineering is that we have automation to update our dependencies automatically. This is safe due to a robust multi-level test suite and a good monitoring stack. Engineering doesn’t have to worry about toil, and security can rest easy knowing that we are up-to-date and there is a fast path to remediation. Win-win!
Kubernetes
I manage our Kubernetes clusters and deployments to them. This involves our Kubernetes architecture, our deployment pipelines, ingress controllers, load balancers, dns, etc. If we have a pod running, I can tell you how it got there and why it’s there.

Me creating my 15th Kubernetes cluster, which will be destroyed in 6 months.
I also oversee our adherence to Kubernetes’ notoriously brutal upgrade cadence and manage our upgrades. So far, I’ve done 18 upgrades without any downtime. A few years ago I finished moving the Kubernetes control plane items to a modularized Terraform setup, our “infrastructure” Kuberenetes deployments to Helm3 charts, and scripted everything else. It’s been a smooth ride since.
Running Kubernetes is like converting to Buddhism. One must embrace ephemeralism.
Cross Functional & All the Things

A fun project I started was our public documentation site. Isn’t the gradient on the button nice?
Then there is everything else. I kind of have my hand in every pie.
I work with our product team, our sales team, our customer success team, and ensure they are technically supported. I formally block out time each week to do “informal” things for other teams. The goal is to increase the output of every engineer, every support person, and every success and salesperson.
I am continually surprised by how a small investment in another team can pay off in spades. Sometimes, they only need a little technical help or a couple of hours of my time to increase their team’s quality of life. In business speak, this is called “force multiplication.” In a way, this is my greatest contribution to the company.
This all is possible because of trust and mutual respect. I respect their time and expertise, and they respect mine. I am happy to think that I have earned it.