When developing for Kubernetes, one of the top things you must consider is what happens when your pod is terminated.
Stateful or stateless, long-lived or short-lived, your pod will eventually terminate.
In a typical case, this would be due to a deployment update, but you could also have a node update leading to termination.
Web servers are susceptible to this, as they will be actively handling requests when the pod starts termination.
Terminating a pod while it is handling requests will lead to failed API requests and HTTP 500s.
If you have good monitoring, you will see these 500s and know something is wrong.
So, let's talk about how to handle this gracefully.
Here is the general order of events for pod termination:
The pod is set to be terminated. You could start this with kubectl delete pod or updating the owning deployment.
The pod is marked as terminating, and the configured grace period starts. The pod is sent SIGTERM so it can start shutting down.
The pod is removed from the service endpoints, so no new requests are sent to it.
While this happens quickly in the Kubernetes control plane, it may take a while for upstream services to stop sending requests.
After the grace period, the pod is forcefully terminated with SIGKILL.
It takes a while for downstream services to remove the pods from service.
For example, if you use the AWS Application Load Balancer, reconciling the target group via AWS APIs will take a few seconds.
Then, it is up to AWS control plane to update the internal load balancer configuration to stop sending traffic.
So there will be a period AFTER receiving SIGTERM where you will still receive new requests.
Therefore, if your code simply "exits" when it receives SIGTERM, you will kill not only the in-flight requests but also new ones coming in.
My preferred Python WSGI server is Gunicorn. It comes with built-in support for graceful shutdowns:
TERM: Graceful shutdown. Waits for workers to finish their current requests up to the graceful_timeout.
So Gunicorn will continue to process existing requests but not new ones.
This is a good default, but it's not enough for Kubernetes because of the downstream deregistration delay.
We need to wait for new connections before shutting down.
If the problem is new connections are still coming in after the pod starts termination... what if we wait longer?
We can increase the terminationGracePeriodSeconds in the pod spec to — let's say — 300 seconds while disabling the graceful_timeout in Gunicorn so it will not shut down at all.
Then, we can just terminate on the final SIGKILL.
This way, pod termination will take 300 seconds and hard shutdown after that period. Our goal here is to wait out the deregistration delay.
But now pod termination takes 300 seconds, which is a long time. That's like... forever.
If your updateStrategy is RollingUpdate with a sequential update strategy and you have a large deployment, this could take a long time to update.
10 pods = 50 minutes of waiting.
You can tune the 300 seconds to be shorter, but you are still not addressing the underlying issue that your termination condition is not reactive to your workload.
What I've found to work the best is to wait for a gap in requests before shutting down.
The idea is that if you have a gap in requests over a certain fixed period of time, you can be confident that the upstream load balancers have removed the pod as a target.
We make two changes to Gunicorn:
Record the time of the last request start.
Modify the Arbiter to check if there has been a gap in requests for a certain period of time before terminating.
from datetime import datetime from gunicorn.arbiter import Arbiter classCustomArbiter(Arbiter): # Seconds to wait for a gap in requests before shutting down SHUTDOWN_REQUEST_GAP =15 def__init__(self,*args,**kwargs): super().__init__(*args,**kwargs) self.last_request_start = datetime.now() self.sigterm_recd =False defhandle_request(self, worker): self.last_request_start = datetime.now() returnsuper().handle_request(worker) defhandle_term(self): """Called on SIGTERM""" if self.sigterm_recd: # Sending 2 SIGTERMs will immediately initiate shutdown raise StopIteration # Prevent immediate shutdown if no requests recently self.last_request_start = datetime.now() self.sigterm_recd =True defmaybe_promote_master(self): """Runs every loop""" super().maybe_promote_master() return self.maybe_finish_termination() defmaybe_finish_termination(self): """Finish the termination if needed""" if self.sigterm_recd: gap =(datetime.now()- self.last_request_start).total_seconds() if gap > self.SHUTDOWN_REQUEST_GAP: raise StopIteration
I have found that this approach works very well against a variety of workloads.
After scanning logs, a 15 second gap is enough to be confident that the pod has been removed from the upstream load balancer with a confidence of 99.9%.
In practice, I have never seen a request come in after the 15 second gap.
We use Kubernetes at $work, and since I am in charge of platform, Kubernetes is my problem. Here's
an interesting problem when trying to secure your Kubernetes workload.
Our pods need to talk to each other over the network. Early on, we decided that each pod
would receive a unique identity in our application's authentication layer. This provides us
maximum auditability -- we can tell exactly which pod performed any given network call. This extends
up one level to the service layer as well. With this system, when a pod receives a network call
it can tell:
What service it is talking to, and
Which pod it is talking to.
It can then allow or deny specific actions based on identity.
This is a great idea! So how do we implement it? The wrinkle is that when programs start, they have nothing. They know who
they are. But how do they prove to other pods who they are?
For ease of reading, I will name the two pods in this example Alice and Bob.
Alice is the pod that wants to prove its identity to Bob.
In general, the way for Alice to prove it is, in fact, Alice is to present something that only that Alice could have.
On Kubernetes, by default, a pod is granted a Kubernetes service account (SA) token. This token
allows it to communicate with the Kubernetes API server.
So our first option is for Alice to send the SA token to Bob. Bob can inspect and check the SA token against the Kubernetes API server.
If the token is valid, Bob knows the caller is Alice.
This is bad because now Bob has Alice's SA token. If Bob were a bad actor (or compromised), then
Bob can use the SA token to issue Kubernetes API calls as Alice. Whatever Alice can do, Bob can do too under this scheme!
Bob can submit the SA token to other services, which would then think Bob is Alice and allow Bob
to act as Alice.
Either case is not acceptable to us. So, we need a way for Alice to prove its identity without giving away the secret to the counterparty.
For the longest time, we compromised on this point by having a central authentication service (Bob in this example) that had access to read Kubernetes service account tokens.1
Alice would send a hashed version of the SA to Bob, and Bob would look through the Kubernetes service secrets and
validate the hash matched what Kubernetes had on record for Alice.
This did not actually solve the problem: now the hash was the valuable McGuffin instead of the SA token.
But at least it did reduce the value of the token being exchanged: now if there was a MITM attack between Alice and Bob, the attacker would only get the hash, not the actual SA token. But now Bob needs access to read ALL tokens! Terrible.
A better method is to have a chain of trust. But what is the root of the chain? We already have something that is the root of all trust: the Kubernetes API server.
Unfortunately, the Kubernetes API server did not have a method of issuing tokens that could be used to prove identity safely... until recently.
Kubernetes 1.20 GA'd Bound Service Account Tokens implemented through Token Projection
and the Token Review API. This allows a pod to request a token that the Kuberenetes API server will inject
into the pod as a file.
The most important part of this KEP (for our purposes) is the token can be arbitrarily scoped. This means that Alice can request a token
that is scoped to only allow it to talk to Bob. Therefore, if Bob were compromised, the attacker would not
be able to impersonate Alice to Charlie.
The Token Review API is the counterpart to Token Projection. It allows a pod to submit a token and a scope
to the Kubernetes API server for validation. The API server is responsible for checking that the token
is trusted and the scopes on the token match the submitted scopes.
This simplifies our wacky hashing scheme and god-mode service and turns it into a simple exchange:
Alice reads the file mounted in the pod.
Alice sends the token to Bob.
Bob submits the token to the Kubernetes API server for validation with the bob scope.
The Kubernetes API server validates the token and the scopes.
Let's walk through a concrete example of this in action.
Alice is very simple:
--- kind: ServiceAccount apiVersion: v1 metadata: name: alice namespace: default --- kind: Pod apiVersion: v1 metadata: name: alice-pod namespace: default spec: serviceAccountName: alice containers: -name: alice image: alpine/k8s command:["/bin/sh"] args:["-c","while true; do sleep 30; done;"] volumeMounts: -name: alice-token mountPath: /var/run/secrets/hfernandes.com/mytoken readOnly:true volumes: -name: alice-token projected: sources: -serviceAccountToken: path: token expirationSeconds:7200 audience: bob ---
Bob is a little more complicated. We must give it permission to talk to the Kubernetes Token Review API. Since Token Review is not namespaced,
we give it a ClusterRole instead of a Role.
--- kind: ServiceAccount apiVersion: v1 metadata: name: bob namespace: default --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: bob rules: -apiGroups:["authentication.k8s.io"] resources:["tokenreviews"] verbs:["create"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: bob roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: bob subjects: -kind: ServiceAccount name: bob namespace: default --- # Bob pod kind: Pod apiVersion: v1 metadata: name: bob-pod namespace: default spec: serviceAccountName: bob containers: -name: bob image: alpine/k8s:1.25.15 # Already has kubectl installed command:["/bin/sh"] args:["-c","while true; do sleep 30; done;"] ---
Now, if we look in alice-pod we find our token:
$ kubectl exec -it alice-pod -- sh / # ls /var/run/secrets/hfernandes.com/mytoken/ token / # cat /var/run/secrets/hfernandes.com/mytoken/token XXXXXXXsecretXXXXXX.YYYYYYYYsecretYYYYYYYYY.ZZZZZZZZZZZZsecretZZZZZZZZZZZZZZ
Let's go into bob-pod and submit this token to the Kubernetes API server for validation:
Note that the JWT is explicit about the serviceaccount being alice, whereas the Token Review API requires
us to parse that out of .status.user.username ("system:serviceaccount:default:alice"). That is kind of annoying. But both clearly contain the pod name.
Let's check our token against the API Server 10 times and see how long it takes -- can we put this API on the hot path?
/apps # for i in $(seq 10); do kubectl create --raw '/apis/authentication.k8s.io/v1/tokenreviews?pretty=true' -f tokenrequest.json -v10 2>&1 | grep ServerProcessing; done HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 5 ms Duration 9 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 4 ms ServerProcessing 2 ms Duration 7 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 6 ms ServerProcessing 1 ms Duration 8 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 4 ms ServerProcessing 4 ms Duration 9 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 6 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 4 ms ServerProcessing 5 ms Duration 10 ms
So typically 1-5ms if you keep a connection to the API server open (and don't have to do the TLS handshake). Not bad!
In our use case, we are only using this to bridge to our main authentication system, so we don't need to do this on the hot path. But it's fast enough we could!
When this API went GA, I jumped on the opportunity to upgrade our interservice authentication.
Implementing this in our application gave us great benefits. We were able to
greatly simplify our code and logical flow,
ditch our wacky hashing scheme,
remove permissions from the god service that could read all service account token secrets,
and increased security by scoping tokens, which removed an entire class of potential attacks.
In addition to moving to Projected Service Account Tokens, we also added checking that the caller IP address matches the IP address of the pod that the token belongs to. This has the added benefit of preventing outside callers from attempting internal authentication at all.
Kubernetes is notorious for having a fast, grueling upgrade cycle. So I am always keeping my ear to the ground to see how the alternatives are doing.
Two container orchestrators I have high hopes for are AWS Elastic Container Service and Fargate. The issue is I have not found a way to implement fine-grain per-container identity proofs in these systems. If you know of a way, please let me know!
Due to our application requirements, we had a central authentication service anyway, so this was not a huge deal. It was already
under stricter security controls than the rest of the applications due to the sensitive nature of its data (eg, password hashes), so we felt comfortable enriching its cluster permissions. ↩
This is a supplementary blog post to one I coauthored that was posted to our corporate blog: Delivering Better Software, Faster.
That blog post came to be because our sales and leadership teams are often questioned on how we are able to move and ship fast without creating unacceptably high risk to our customers. Having lived in DevOps land for years,
that question hurts my soul.
My experience is that the healthcare IT industry is a giant, slow, lumbering monstrosity. A slug where the head is, at best, in the early 2010s and the tail is still in the 1980s. Worse, large parts of the industry are struggling with the transformation of healthcare models. The whole thing is broken.
Healthcare IT still uses a lot of faxes.
Fax machines have a carve-out in HIPAA and they will be with us forever.
It seems like magic when we show up and offer them a SaaS solution, demonstrate we can ship changes for them in under a week, offload compliance burden, reduce staff toil, and get better patient outcomes. To the captains of these large vessels, heaving to turn and facing their own choppy waters, something that looks like magic is to be questioned as a scam or requiring a hidden tradeoff. Fair enough. One of the frequent takes we hear is some form of: “I interpret your pride in your ability to move fast as actually being indicative of your willingness to cut corners or your negligence in ignoring downstream effects.”
And it’s so… wrong for so many reasons. So we write a customer-facing blog post on the ABCs of our pipeline to assure our customers that the process is safe. We had a more detailed version that got cut down for ― in my own opinion and not representing the views of my company ― being too preachy.
But guess what? This is my blog and I can be preachy. The joke is on them, too: In my capacity as owner of DevOps, I think about the safety of our product and the productivity of our developers literally every single day. So I have opinions.
In my capacity overseeing DevOps, I have several key areas of responsibility: developer productivity, product security, and availability. Over the past five years, my approach to software engineering has transformed into one of risk management. Contrary to some people’s gut instincts, the tenets of risk management tell us that reducing risk goes hand in hand with maximizing developer productivity and shipping speed.
To understand why, we need to address three things:
What is risk?
Why do some people think that moving fast requires a commensurate increase in risk?
Why does good engineering hygiene cause moving fast to decrease risk?
The principal risk that engineering ― as an organization ― considers is the risk to our customers and, by extension, our business. We are a strategic technology choice, and our customers depend on us for their ability to do business. We know that reputation is everything and is something that’s difficult to repair once stained. Our goals align with our customers: we protect our reputation with our customers and also protect our customers' reputation with their patients.
What are our customers worried about? Here’s a handful of issues we think about: that our product will go down and halt their business, that our product will leak data and lead to HIPAA violations, and that our product will be a bad experience for the providers or their patients.
Availability and security are obviously technical concerns in the hands of the engineering team. Many people would say experience is in the hands of product management, but it’s jointly managed with engineering with the addition of an iterative loop, but let’s talk about that later.
A unique thing about risk is that risk is a fractal that unfurls into many upstream risks. Let’s take the example of “product availability” because it’s easy to illustrate. What could lead to product availability risk?
Product crashes
Platform instability
Datacenter outages
Addressing risk requires addressing upstream risks recursively. “Bad code being released” has its own upstream risk contributors. You must recursively manage risk until you are satisfied that each has a countermeasure prepared to alleviate risk to an acceptable degree. Here, risk management relates to other engineering methodologies: this is the flip side of the ubiquitous “five whys.”
Risk satisfaction. Your taste for particular types of risk will vary from organization to organization. For example, I am willing to address the risk of a datacenter going down by going multi-AZ or multi-region. However, I don’t consider it in scope to manage the risk of (to think of an extreme example…) a nuclear exchange destroying every AWS region. This is a clear example, but some tradeoffs are not so clear and have subtle tradeoffs. As always, engineering tradeoff decisions can be more of an art than a science. Finally, it’s worth noting that some organizations do plan to be available after nuclear exchanges and have appropriate contingency plans!
Risk tolerance varies!
Where does the myth of “moving fast requires increased risk” come from? The answer is that it comes from healthcare IT’s perpetual 1980-2010 existence. Healthcare IT is used to the enterprise-software model of owning their own hardware, owning their own deployments, having a multi-year installation and migration headed by a project manager, and having a massive downtime-requiring upgrade every few years. It’s Enterprise Software (capital E capital S). As an institution, that is what they are familiar with and what their instinct tells them to reach for. They do not understand the hands-off SaaS model. In short, they are stuck behind the curve on how modern software is developed, deployed, and maintained. Again: fair enough. They are not software companies.
That is why healthcare executives are immediately suspicious when you pitch a SaaS model and mention you release to production twice a week. All they know of “healthcare software releases” is what has been reported up the chain to them from IT. Namely, constant calls for maintenance periods and notifications to executives about risks of upgrading their Big Software Package. Healthcare execs are not dumb. Rather, we are presenting them with a fundamentally different technical ecosystem. As if that’s not enough, that’s also underpinning a fundamentally different care approach on the business side. There are a lot of departures from the old Enterprise Software model that healthcare execs have to wrap their head around:
Modern DevOps methodologies flip the old style of software development on its head. “What’s new is inherently risky.”
SaaS removes operational burden (and some decision-making!) from IT. They have to trust their vendor to not radically change the product without notice. Additionally, they are used to managing their own known risks. They don’t immediately see the value of us reducing operational complexity if they feel they already have it handled. The upside is discounted and the downside is clear: lack of control.
No waterfall model release schedule. No two-quarter release testing phase before every deployment. In their old model, the big testing phase surely caught would-be devastating bugs. How can a SaaS vendor perform as-thorough of a test in the two days before release? Surely they must be sacrificing assurance and thereby increasing risk! (Not so!)
Agile development means we will work hand-in-hand with them to improve our product over time in an iterative loop. Again, this differs from the waterfall model where they will throw a big requirements document at us and we’ll meet back in a few quarters. Rather, the role of the project manager fundamentally changes to an ongoing-cooperative role. MVPs are rolled out quickly behind feature flags and immediately handed over to the customer for testing at their leisure. If you are used to the old model, the first (and only?) thing you hear is “un-QAd code is released to production.”
So, given a familiarity with the downsides and tradeoffs of the old model of on-prem Enterprise Software, hearing an offhand comment about how fast we can ship features would lead you to think we are cutting corners. The only way to get out of that mindset is to deep dive into modern software methodologies, which is not their area of expertise. So here is my crash course in modern software methodologies.
The principles of software engineering combined with the principles of risk management lead us to a simple opinion on how to execute: pull as much risk possible, as soon as possible. As time goes on, the consequences of risk increase. Therefore, the earlier the risk is experienced, the more likely it is to be caught while the consequences are small.
All the investments in tooling, developer experience, and process is intended to move towards the red line's risk profile.
We want to experience as much risk as early as possible so that the long-term "tail" has less risk.
This means we catch more bugs earlier, generally before they are released.
Risk management meshes with three other principles of modern software development:
Releasing early.
Releasing often.
Continuously evolving the process.
These three principles synergize together to increase development velocity while decreasing risk. Additionally, we further add specific risk mitigations to each step to fit our risk tolerance.
Large waterfall roadmaps don’t work. They are inefficient. The time between handing off the requirements for development and testing the product is too long. That time difference adds risk, lets downstream code ossify, and ultimately increases the cost to get to the final product. Agile development tells us to release a minimum viable product to the customer as fast as possible in order for the customer to influence the development of the product as early as possible.
To further reduce risk, we employ feature flags to keep in-development changes visible only to the customers we are working with. Along with frequent releases and contact with customers, we can experiment and the product can quickly grow in the right direction. This maximizes developer productivity while also getting customers exactly what they want, faster.
In a nutshell, modern DevOps dogma tells us that breaking up large changes to a system (read: the infrequent Big Software Package Upgrade) into a series of smaller changes leads to faster development velocity and ultimately reduces risk. There are a few reasons for this, but at its simplest, as you approach the tiniest change, the risk approaches zero or is at least confined to a single changed thing. It’s easier to understand how varying a single element affects the overall system rather than many hundreds of varying elements. This is what “release often” means. As the release package size increases, complex interplay arises between the changing components and the state space for what needs to be tested explodes exponentially.
Releasing often also means that there are more opportunities for adjusting things on production. Frequent releases mean that there is no fear of “missing the train” for a release schedule. Don’t worry! The train will be back in two days!
Perhaps the most important aspect of modern software development and DevOps is the obsessive focus on The Process. We routinely scrutinize the entire software development lifecycle for security and speed. Again, pushing as much risk to the front is key. There is a cultural aspect to this as well: when we experience even a minor issue, we always ask two questions:
How can we immediately fix the issue?
How can we prevent this from happening in the future?
The second question must be answered with an automated test if at all possible. This prevents the issue from ever occurring in the future: we will commit a test in our code to check for this failure condition early in the process.
The Process is distilled into a multi-step action list in the main blog post, but briefly, the developer loop of our software development lifecycle is:
Providing a strong baseline developer experience from a “known-good” state.
Unit tests are required to cover all codepaths, enforced by tooling.
Code reviews by engineers with competence in the area of the product being changed.
Staging environment releases that exercise many failure scenarios.
System / Integration tests that drive all common or critical product usage patterns.
Manual QA & release approval.
Feature flags to allow partial releases of product changes to a subset of users.
We have invested in The Process because each step pulls risk forward and catches mistakes early. For the most part, all of this happens fast and automatically through tooling and tests. Code cannot even make it to staging unless it has been linted, tested, and covered. Then even more assurance and de-risking measures run. By the time any code makes it to release, it has been exercised and tested for all potential code paths and has been looked at by multiple pairs of eyes in different ways.
We are largely successful. Releases are very boring affairs. A single engineer reviews a dashboard of green check marks, gets formal product management and engineering approval, and runs yet more tooling that orchestrates release. And voilà, the databases are patched, the code is live and serving real customers! All said and done, a release to production takes about an hour of an engineer’s time. Again, the risk has been moved forward so much that we encounter very few problems by the time we get to production release.
We have spent millions of dollars creating and improving The Process because it de-risks quickly and in a fashion that scales up as the number of developers we have grows and our product becomes larger. The risk reduction afforded to us by strong guard rails and our investments in the process allows our developers to move fast and not break things! What we get is a massive boost to developer productivity and confidence in the final product.
In short, risk and developer velocity are both largely functions of engineering hygiene. Increasing velocity does not increase risk. In fact, with proper engineering hygiene, increasing velocity reduces risk due to breaking up risky operations into smaller, more manageable chunks!
So, when DevOps people think of reducing the risk further during stable operations, we prefer hitting the gas instead of the brake. Doing so benefits us from the tailwind of our expensive process investments.
Building services today often require integration with other web services. That means sharing your customer's data with another company. Your users have never heard of this company before, yet they will hold their information. That sucks, and it can seem like a betrayal of your users' trust!
Hopefully, you are a good steward of your user's data and would avoid sharing their data if possible. I cannot stress this enough: as a software engineer in the 2020's -- the age of data breaches and data reselling -- you have a moral imperative to safeguard your user's data to the best of your ability. If a moral duty is not good enough and you are in a regulated field, you might have a legal duty too! Either way, a good rule of thumb is to not go blasting your user's data all over the internet.
That being said, some features require sharing data. Oftentimes there is a tradeoff between user experience and privacy. Sometimes sharing data is unavoidable without significant user experience degradation. In this case, you might have to share data.
I have two pieces of advice for doing this safely and while respecting your users. First: be honest with your users. Second: mask their data from your service provider.
Google Cloud Platform emails me every time they change who they send my data to. Thanks, GDPR!
Be upfront and honest with your users about a) what types and b) with whom their data is being shared. Consider prompting the user in a modal before their first use of a feature that would share data. It's like a permission popup for data sharing! Data sharing should be opt-in (not opt-out!). If they decline, that's fine! Dependent features can be disabled for them.
The GDPR promulgated requirements for identifying "data subprocessors" for companies operating (or having users) in the European Union. It requires companies to disclose who they are sharing data with publicly! US users benefit from this EU regulation as well: large multinationals already have to do data bookkeeping for the EU, and we can see their disclosures.
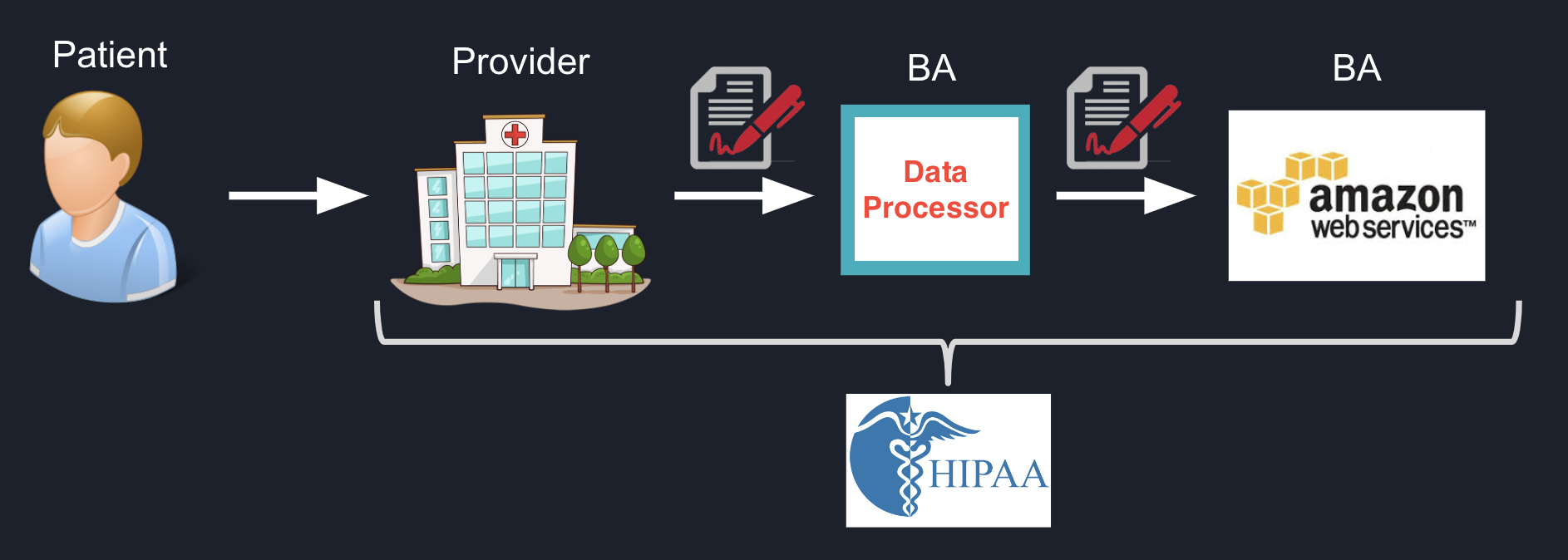
In the US, we have regulations like HIPAA that apply only to particular use cases in healthcare. Under HIPAA, sharing PHI requires signing a Business Associate Agreement. This forms a "chain of trust" between a patient, their healthcare provider (covered entity), and the healthcare provider's successive data subprocessors.
HIPAA requires signing a business associate agreement (BAA) with data processors before sharing PHI.
This forms a recursive chain of trust for the data.
Finally, it's worth noting that some states are making progress in legislating this area (like the California Consumer Privacy Act). Get your act together now before Congress forces you to do it against a deadline!
I will state the obvious: share the least amount of data possible with the other service. Seriously, leave data fields blank if you can. Provide the minimum amount of data necessary and no more. Most people can reason this out on their own. However, providing the service only encrypted User IDs is important and non-obvious.
Every third-party service you share data with should get a different apparent user ID for the same user. This might seem like a circus to implement and consume, but it provides your users with robust anonymization and privacy guarantees.
If breached, Service A and Service B cannot correlate user information using User ID. It's an excellent quality to have in the age of data breaches.
Encrypting User IDs doesn't apply to just third-party services you push data to: you should also apply it to services that integrate with your service and read your APIs. For example, every OAuth application that calls your APIs should get different User ID values.
In addition to privacy benefits, we gain anti-abuse features too: a side effect of unique/per-app User IDs is that an API abuser cannot use multiple API integrations to consume more quota than they are allowed. For example, the Riot League of Legends API encrypts player IDs. This disincentivizes running numerous projects in parallel to get around per-API key rate limits.
I am fortunate enough to be able to shape (in some small part) the engineering culture at my company. Part of that comes from realizing that engineering culture comes from consensus more than other cultures, which means discussing topics with fellow engineers and advocating for your position. "Culture" here is not dictated but mutually agreed upon by the engineers.1
One of the things I have advocated is postmortem culture. Occasionally, something will happen that makes someone say, "that was bad enough that we don't want it ever to happen again." This is a key phrase indicating that you should write a postmortem!
A postmortem memorializes want went wrong, the actions and circumstances that led up to it, describes how the situation was defused, and creates specific action items to prevent it from happening again.
One cannot fully resolve an incident until a postmortem is written. Postmortems are core to knowledge transfer and creating best practices. "Best practices" can seem like an amorphous abstraction, but seeing a specific case where they help or would have prevented an incident is a compelling demonstration of the practice's value.
However, writing a postmortem can look like a lot of work coming off an incident (even a minor one!). We've made a few improvements to the postmortem process to remove some roadblocks. Writing postmortems should not be that hard!
We've taken four specific steps to improve and encourage postmortem culture:
Starting with an empty document is difficult. Postmortem templates put you on rails to get started.
Postmortem Guidelines. Engineers used to reference older postmortems and make new ones resembling those. So the quality varied and trended down over time. Now, we have a document that provides strong guidance on writing postmortems, from start to end. We explicitly outline the goals of a postmortem, the process, the feedback loop, and the dos and don'ts.
Postmortem Templates. Beginning a postmortem is difficult. Having a base template that you can copy/paste makes creating them a lot easier: you start by just filling out fields! Starting with a blank page is hard. Starting with some boxes is much easier. And, as you explore further, you add more details!
Wide distribution. We distribute our postmortem documents to the entire engineering organization by default and optionally even wider to the rest of the company. Postmortems are essential documents, and an emphasis on distribution is a clear indicator of value. We don't write these just for fun!
Blameless postmortems. When writing a postmortem, don't name anyone -- this removes blame and unlocks the ability to dive deeper. More on this in a bit.
Writing postmortems is easy and impactful when you fuse these items. Postmortems no longer look like a massive effort to new engineers, and we encourage writing a postmortem for less-than-outage level events.
The most significant improvement to the postmortem process we've made is officially moving to blameless postmortems. Blameless postmortems involve... not blaming anyone. You don't name names. At most, you name roles. You realize that a person did not cause an incident, but rather a process did.
Obviously git blame is fine for code archaeology. But blaming engineers when failures happen is not.
Blameless postmortems turn introspection from "a time to play the musical-chair blame game" into an opportunity for learning and growth. By removing blame, you also remove politics. There are plenty of positive knock-on effects that come from dampening the effects of politics, including the ability to look under otherwise "politically active" rocks during your root cause analysis.
Moreover, I don't want engineers to feel bad. That is not the goal. Their name should not be tied permanently to an outage in some official document. The goal is for Engineering as an organization to not repeat that mistake and remove the conditions that made that mistake even possible.
I occasionally get pushback from other engineers about not including names in postmortems. Truthfully, I still do not fully understand why this is the case. I have one theory that it's at odds with an engineer's initial instinct to include as much detail as possible. I think the argument comes from wanting completeness of the record. However, I don't believe names add meaningful detail to the record. It could have been anyone in that role, and the postmortem should reflect that.
Large companies get their postmortems wrong all the time. Here's a good postmortem and a bad postmortem:
Great postmortem culture: Amazon's S3 outage, where the engineer who took down S3 was not named or shamed and not disciplined. Amazon correctly makes it clear that it was the process that failed and focuses on how they will technically prevent this in the future.
Bad postmortem culture: Salesforce DNS outage, where they blame an engineer for the outage. They focus on the engineer instead of the process. Beyond showing a lack of introspection from the engineering organization, a postmortem like this telegraphs a toxic engineering culture. "More training" is such a weasely and meaningless statement. If their engineers regularly circumvent their process to perform their job, the process is wrong. Not the engineers. Salesforce's postmortem reads like an executive needed someone to blame. 2
All companies should adopt at least a blameless postmortem process. It will help your organization be honest with itself and fix the underlying root cause instead of sweeping issues under the rug.
This does not mean that stalemates are allowed to develop. If no clear progress is being made, it's always an option to "disagree and commit." ↩
Things like this are what cause engineers to think twice before working for a company like Salesforce. I don't want to work at a place where I am afraid that a mistake could cost me my job and management would single me out as the reason an outage happened. ↩