When developing for Kubernetes, one of the top things you must consider is what happens when your pod is terminated.
Stateful or stateless, long-lived or short-lived, your pod will eventually terminate.
In a typical case, this would be due to a deployment update, but you could also have a node update leading to termination.
Web servers are susceptible to this, as they will be actively handling requests when the pod starts termination.
Terminating a pod while it is handling requests will lead to failed API requests and HTTP 500s.
If you have good monitoring, you will see these 500s and know something is wrong.
So, let's talk about how to handle this gracefully.
Here is the general order of events for pod termination:
The pod is set to be terminated. You could start this with kubectl delete pod or updating the owning deployment.
The pod is marked as terminating, and the configured grace period starts. The pod is sent SIGTERM so it can start shutting down.
The pod is removed from the service endpoints, so no new requests are sent to it.
While this happens quickly in the Kubernetes control plane, it may take a while for upstream services to stop sending requests.
After the grace period, the pod is forcefully terminated with SIGKILL.
It takes a while for downstream services to remove the pods from service.
For example, if you use the AWS Application Load Balancer, reconciling the target group via AWS APIs will take a few seconds.
Then, it is up to AWS control plane to update the internal load balancer configuration to stop sending traffic.
So there will be a period AFTER receiving SIGTERM where you will still receive new requests.
Therefore, if your code simply "exits" when it receives SIGTERM, you will kill not only the in-flight requests but also new ones coming in.
My preferred Python WSGI server is Gunicorn. It comes with built-in support for graceful shutdowns:
TERM: Graceful shutdown. Waits for workers to finish their current requests up to the graceful_timeout.
So Gunicorn will continue to process existing requests but not new ones.
This is a good default, but it's not enough for Kubernetes because of the downstream deregistration delay.
We need to wait for new connections before shutting down.
If the problem is new connections are still coming in after the pod starts termination... what if we wait longer?
We can increase the terminationGracePeriodSeconds in the pod spec to — let's say — 300 seconds while disabling the graceful_timeout in Gunicorn so it will not shut down at all.
Then, we can just terminate on the final SIGKILL.
This way, pod termination will take 300 seconds and hard shutdown after that period. Our goal here is to wait out the deregistration delay.
But now pod termination takes 300 seconds, which is a long time. That's like... forever.
If your updateStrategy is RollingUpdate with a sequential update strategy and you have a large deployment, this could take a long time to update.
10 pods = 50 minutes of waiting.
You can tune the 300 seconds to be shorter, but you are still not addressing the underlying issue that your termination condition is not reactive to your workload.
What I've found to work the best is to wait for a gap in requests before shutting down.
The idea is that if you have a gap in requests over a certain fixed period of time, you can be confident that the upstream load balancers have removed the pod as a target.
We make two changes to Gunicorn:
Record the time of the last request start.
Modify the Arbiter to check if there has been a gap in requests for a certain period of time before terminating.
from datetime import datetime from gunicorn.arbiter import Arbiter classCustomArbiter(Arbiter): # Seconds to wait for a gap in requests before shutting down SHUTDOWN_REQUEST_GAP =15 def__init__(self,*args,**kwargs): super().__init__(*args,**kwargs) self.last_request_start = datetime.now() self.sigterm_recd =False defhandle_request(self, worker): self.last_request_start = datetime.now() returnsuper().handle_request(worker) defhandle_term(self): """Called on SIGTERM""" if self.sigterm_recd: # Sending 2 SIGTERMs will immediately initiate shutdown raise StopIteration # Prevent immediate shutdown if no requests recently self.last_request_start = datetime.now() self.sigterm_recd =True defmaybe_promote_master(self): """Runs every loop""" super().maybe_promote_master() return self.maybe_finish_termination() defmaybe_finish_termination(self): """Finish the termination if needed""" if self.sigterm_recd: gap =(datetime.now()- self.last_request_start).total_seconds() if gap > self.SHUTDOWN_REQUEST_GAP: raise StopIteration
I have found that this approach works very well against a variety of workloads.
After scanning logs, a 15 second gap is enough to be confident that the pod has been removed from the upstream load balancer with a confidence of 99.9%.
In practice, I have never seen a request come in after the 15 second gap.
We use Kubernetes at $work, and since I am in charge of platform, Kubernetes is my problem. Here's
an interesting problem when trying to secure your Kubernetes workload.
Our pods need to talk to each other over the network. Early on, we decided that each pod
would receive a unique identity in our application's authentication layer. This provides us
maximum auditability -- we can tell exactly which pod performed any given network call. This extends
up one level to the service layer as well. With this system, when a pod receives a network call
it can tell:
What service it is talking to, and
Which pod it is talking to.
It can then allow or deny specific actions based on identity.
This is a great idea! So how do we implement it? The wrinkle is that when programs start, they have nothing. They know who
they are. But how do they prove to other pods who they are?
For ease of reading, I will name the two pods in this example Alice and Bob.
Alice is the pod that wants to prove its identity to Bob.
In general, the way for Alice to prove it is, in fact, Alice is to present something that only that Alice could have.
On Kubernetes, by default, a pod is granted a Kubernetes service account (SA) token. This token
allows it to communicate with the Kubernetes API server.
So our first option is for Alice to send the SA token to Bob. Bob can inspect and check the SA token against the Kubernetes API server.
If the token is valid, Bob knows the caller is Alice.
This is bad because now Bob has Alice's SA token. If Bob were a bad actor (or compromised), then
Bob can use the SA token to issue Kubernetes API calls as Alice. Whatever Alice can do, Bob can do too under this scheme!
Bob can submit the SA token to other services, which would then think Bob is Alice and allow Bob
to act as Alice.
Either case is not acceptable to us. So, we need a way for Alice to prove its identity without giving away the secret to the counterparty.
For the longest time, we compromised on this point by having a central authentication service (Bob in this example) that had access to read Kubernetes service account tokens.1
Alice would send a hashed version of the SA to Bob, and Bob would look through the Kubernetes service secrets and
validate the hash matched what Kubernetes had on record for Alice.
This did not actually solve the problem: now the hash was the valuable McGuffin instead of the SA token.
But at least it did reduce the value of the token being exchanged: now if there was a MITM attack between Alice and Bob, the attacker would only get the hash, not the actual SA token. But now Bob needs access to read ALL tokens! Terrible.
A better method is to have a chain of trust. But what is the root of the chain? We already have something that is the root of all trust: the Kubernetes API server.
Unfortunately, the Kubernetes API server did not have a method of issuing tokens that could be used to prove identity safely... until recently.
Kubernetes 1.20 GA'd Bound Service Account Tokens implemented through Token Projection
and the Token Review API. This allows a pod to request a token that the Kuberenetes API server will inject
into the pod as a file.
The most important part of this KEP (for our purposes) is the token can be arbitrarily scoped. This means that Alice can request a token
that is scoped to only allow it to talk to Bob. Therefore, if Bob were compromised, the attacker would not
be able to impersonate Alice to Charlie.
The Token Review API is the counterpart to Token Projection. It allows a pod to submit a token and a scope
to the Kubernetes API server for validation. The API server is responsible for checking that the token
is trusted and the scopes on the token match the submitted scopes.
This simplifies our wacky hashing scheme and god-mode service and turns it into a simple exchange:
Alice reads the file mounted in the pod.
Alice sends the token to Bob.
Bob submits the token to the Kubernetes API server for validation with the bob scope.
The Kubernetes API server validates the token and the scopes.
Let's walk through a concrete example of this in action.
Alice is very simple:
--- kind: ServiceAccount apiVersion: v1 metadata: name: alice namespace: default --- kind: Pod apiVersion: v1 metadata: name: alice-pod namespace: default spec: serviceAccountName: alice containers: -name: alice image: alpine/k8s command:["/bin/sh"] args:["-c","while true; do sleep 30; done;"] volumeMounts: -name: alice-token mountPath: /var/run/secrets/hfernandes.com/mytoken readOnly:true volumes: -name: alice-token projected: sources: -serviceAccountToken: path: token expirationSeconds:7200 audience: bob ---
Bob is a little more complicated. We must give it permission to talk to the Kubernetes Token Review API. Since Token Review is not namespaced,
we give it a ClusterRole instead of a Role.
--- kind: ServiceAccount apiVersion: v1 metadata: name: bob namespace: default --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: bob rules: -apiGroups:["authentication.k8s.io"] resources:["tokenreviews"] verbs:["create"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: bob roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: bob subjects: -kind: ServiceAccount name: bob namespace: default --- # Bob pod kind: Pod apiVersion: v1 metadata: name: bob-pod namespace: default spec: serviceAccountName: bob containers: -name: bob image: alpine/k8s:1.25.15 # Already has kubectl installed command:["/bin/sh"] args:["-c","while true; do sleep 30; done;"] ---
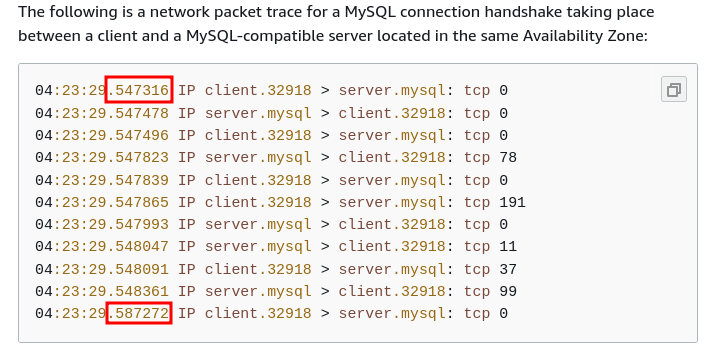
Now, if we look in alice-pod we find our token:
$ kubectl exec -it alice-pod -- sh / # ls /var/run/secrets/hfernandes.com/mytoken/ token / # cat /var/run/secrets/hfernandes.com/mytoken/token XXXXXXXsecretXXXXXX.YYYYYYYYsecretYYYYYYYYY.ZZZZZZZZZZZZsecretZZZZZZZZZZZZZZ
Let's go into bob-pod and submit this token to the Kubernetes API server for validation:
Note that the JWT is explicit about the serviceaccount being alice, whereas the Token Review API requires
us to parse that out of .status.user.username ("system:serviceaccount:default:alice"). That is kind of annoying. But both clearly contain the pod name.
Let's check our token against the API Server 10 times and see how long it takes -- can we put this API on the hot path?
/apps # for i in $(seq 10); do kubectl create --raw '/apis/authentication.k8s.io/v1/tokenreviews?pretty=true' -f tokenrequest.json -v10 2>&1 | grep ServerProcessing; done HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 5 ms Duration 9 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 4 ms ServerProcessing 2 ms Duration 7 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 6 ms ServerProcessing 1 ms Duration 8 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 4 ms ServerProcessing 4 ms Duration 9 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 6 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 3 ms ServerProcessing 1 ms Duration 5 ms HTTP Statistics: DNSLookup 0 ms Dial 0 ms TLSHandshake 4 ms ServerProcessing 5 ms Duration 10 ms
So typically 1-5ms if you keep a connection to the API server open (and don't have to do the TLS handshake). Not bad!
In our use case, we are only using this to bridge to our main authentication system, so we don't need to do this on the hot path. But it's fast enough we could!
When this API went GA, I jumped on the opportunity to upgrade our interservice authentication.
Implementing this in our application gave us great benefits. We were able to
greatly simplify our code and logical flow,
ditch our wacky hashing scheme,
remove permissions from the god service that could read all service account token secrets,
and increased security by scoping tokens, which removed an entire class of potential attacks.
In addition to moving to Projected Service Account Tokens, we also added checking that the caller IP address matches the IP address of the pod that the token belongs to. This has the added benefit of preventing outside callers from attempting internal authentication at all.
Kubernetes is notorious for having a fast, grueling upgrade cycle. So I am always keeping my ear to the ground to see how the alternatives are doing.
Two container orchestrators I have high hopes for are AWS Elastic Container Service and Fargate. The issue is I have not found a way to implement fine-grain per-container identity proofs in these systems. If you know of a way, please let me know!
Due to our application requirements, we had a central authentication service anyway, so this was not a huge deal. It was already
under stricter security controls than the rest of the applications due to the sensitive nature of its data (eg, password hashes), so we felt comfortable enriching its cluster permissions. ↩
If you are a tech company on the AWS cloud, buying AWS Support is one of the best things you can do for your business. It immediately gives you access to incredibly skilled professionals to fill gaps in your knowledge. While it's obvious you can reach out when you are having problems, you can reach out for guidance, too. Support has saved me weeks of work with a few deep insights into technical issues they foresaw me running into down the line. RDS? Migrations? VPNs? Exotic VPC layouts? If you are doing anything remotely interesting, then they can help and advise.
You still have options for the rare case where frontline support can't help. They are not afraid of escalating: when things aren't making sense, they engage the same engineering team that works on the service to help. What a great thing to have -- you can hear exactly from the service developers! I've had wacky permissions policies explained to me, workarounds for internal implementation issues, and you can get timelines for when they will ship a feature you want -- sometimes you can wait out your work. You can even put in feature requests. I've seen my requests turn into real features!
From a business perspective, it's also an insurance policy against things going wrong and gives you options when it does. On the business plan you can access support in at most 1 hour. If your product depends on AWS to work, this is a no-brainer. If we're having an outage, I'd rather tell my customer that I am on the phone with AWS engineers rather than telling my customer that I didn't opt into a better support plan.
The issue is that support is expensive. Each AWS account you enroll in support has a cost of MAX($100, 10% of spend) 1. Did you get that? Per account! That's insane in a world where AWS has declared that the best practice is a multi-account setup. To enroll your entire multi-account organization in support, you must pay (drumroll please...) at least $5,000 every month. Just on Support.
AWS is being hypocritical: they preach the virtues of multi-account on the one hand and then make it financially painful to do so on the other.
Best Practices: Multi-Account Setup
Master Account
+ $100
Identity Account
+ $100
Log Archive Account
+ $100
Audit Account
+ $100
Security Account
+ $100
Shared Services Account
+ $100
Total
🤑💸
They need to add an organization-wide plan that doesn't cost an arm and a leg. The Business plan needs to be made multi-account.
In an effort to show how dumb AWS Support pricing is, I will show how to get around it. Ultimately, the $200 fixes cost washes away and the 10% additional cost becomes the main factor. But you can get around that!
Create an AWS organization and create a single subaccount.
Run all of your workloads in your sub-account.
Buy all of your RIs in your master account.
Enroll only your sub-account in a support plan.
Now you have a situation where the 10% bill does not apply to your RI purchases, but you will receive support for those resources in the subaccount. This is an artifact of AWS Support billing model. It's a stupid model and they should change it. If they had affordable (not $5,000+/mo!) options, it would be a braindead simple choice to just enroll the entire organization. Then this dumb hack would not work.
I hope that by showing how to avoid dumb per-account support billing, AWS will consider adding better org-wide options. It's the only way they should be billing support.
We extensively use CircleCI as our CI provider. We run our entire test suite on CircleCI machines for all new commits in all PRs across our microservice repositories.
Like most other CI providers, they integrate with Github's webhooks so that CircleCI gets pinged to start running CI tests whenever new code is pushed. This is 80% of our CI workload, and this 80% works great. Let's talk about the other 20%.
Our other major use case is running our entire end-to-end test suite against our pre-prod staging cluster. This happens after any microservice merges a PR.
We only want one deployment to run against our shadow cluster at a time. We need deployments to be serialized because:
We need to not deploy new versions of apps over eachother. Some changes migrate state, and running duplicate migrations
(or varied migrations but at the same time) is a bad idea.
Deploying one thing at a time makes it very easy to tell which change caused breakage.
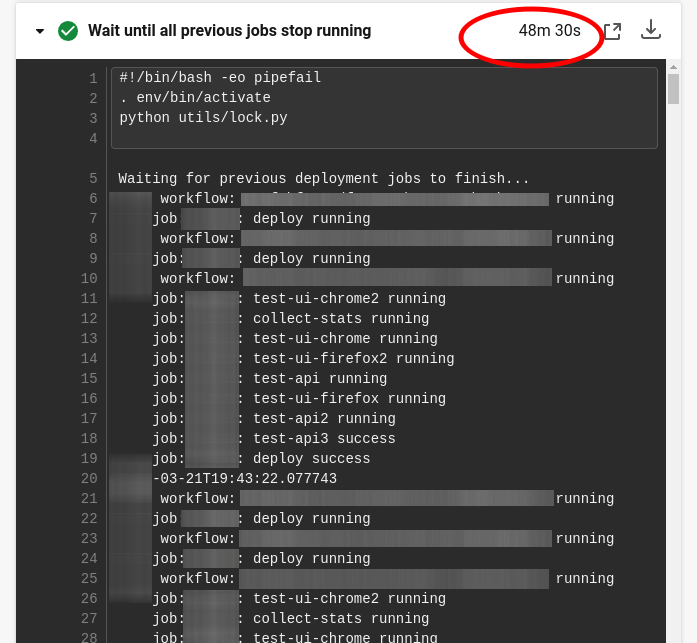
The net effect of this is that you have many builds running and spending money, and only the first one to start is actually doing anything meaningful. The others are just waiting their turn.
For example, here's a particularly bad case where we wasted 48 minutes waiting for previous jobs to be done:
You can see that, just like the recommended script linked earlier, we just have to spin and wait.
This is one of my biggest complaints about CircleCI. All projects that need to serialize deployments (which is... almost all of them?) also need to wastefully spend resources in wait loops.
If I were a little more conspiratorial, I might think that CircleCI is incentivized not to implement serialization properly because all the credits spent on spin-locking would go away.
I dug through the last 30 days of pre-prod test pipeline data to figure out how much time and money we waste on this.
74% of the Deployment time and 5% of total pipeline time is spent waiting for serialization. This is money being thrown down the drain because CircleCI does not have proper serialization support.
You could probably hack together a solution with API Gateway, webhooks, and CircleCI API triggers. But then you would lose pipeline progress visibility. The last thing you want is for your engineers to wonder why their build isn't on the CircleCI dashboard.
CircleCI's backend is the best place to start jobs serially. My top CircleCI wish is to add serialization support to circleci.yml configuration files. It's been over a decade since its launch. How much longer will it be until we get this basic functionality?
This is a follow-up to my previous blog post, SQS Slow Tail Performance. That post has much more detail about the problem. For various work-related reasons, I am finally revisiting SQS performance. It's my white whale, and I think about it frequently. And I've discovered at least one thing!
In my previous post, I mentioned both that HTTP "cold-start" times and low HTTP Connection: keep-alive times could be a contributing factor. And, after some more investigating, it turns out I was sort of right. Sort of.
HTTP Keep-Alive is when the server indicates to the client that the TCP connection should be kept open after the HTTP Response is sent back. Normally (under HTTP/1), the TCP connection would be closed after the response is completed. Keeping it alive lowers the TCP/TLS overhead associated with making a request. When using keep-alive, you only pay the overhead for the first request and all subsequent requests get to piggyback on the connection.
Persistent connections are so performance-enhancing that the HTTP/1.1 specification makes them the default (§8.1.2.1)! The method by which the server indicates to the client that it wants to close the connection is by sending Connection: close. But the server can just close the connection anyways without warning.
I ran some more tests like last time. Importantly, the difference from the testing I did in my previous post was that I executed more sqs:SendMessage calls serially. Last time I did 20. This time I did 180. It turns out that the magic number is... 🥁🥁🥁 80!
Every 80 messages, we see a definite spike in request time! To be fair, we don't only see a latency spike on the 81st message, but we always see it every 80.
And what do you know? 1-1/80 = 98.75. This is where our definite 99th percentile latency comes from! So what the heck is happening every 80 messages?
To test sqs:SendMessage latency, I set up an EC2 instance in order to run calls from within a VPC. This should minimize network factors. Typically, we see intra-vpc packet latency of about 40 microseconds (the best of the three largest cloud providers; study courtesy of Cockroach Labs). So any latency we see in our calls to SQS can reasonably be attributed to just SQS and not the network between my test server and SQS servers.
Here are the test parameters:
Queue encryption enabled with the default AWS-provided key.
The data key reuse period for encryption was 30 minutes.
Message expiration of 5 minutes. We'll never consume any messages and instead, choose to let them expire.
Visibility timeout of 30 seconds. This should not affect anything as we are not consuming messages.
Message Payload of 1 kB of random bytes. Random so that it's not compressible.
Concurrent runs capped to 16.
I ran 100 runs, each consisting of 180 serial sends each and then aggregated the results. Here are the results, plotting the p75 latency across all the calls at a given position:
Notice that every 80 messages we see a big bump in the p75 latency? We have high call times on the 1st, 81st, and 161st messages. Very suspicious!
The AWS client library I use is boto3, which also returns response headers. As it turns out, SQS is explicitly sending Connection: close to us after 80 messages being sent on a connection. SQS is deliberately closing the connection! You'll typically see this behavior in distributed systems to prevent too much load from going to one node.
However, we don't just see slow calls every 80 sends. We see slow calls all over the place, just less frequently. Here is the max() call time from each position.
This seems like evidence that the connections are being dropped even before the 80th message. Boto3 uses the urllib2 under the hood, and urllib comes with excellent logging. Let's turn it on and see what's going on!
And, after executing a single serial run we see connection resets exactly where we'd expect them.
Unfortunately, we don't also see "silently dropped connections" (aka, TCP connections closed without a Connection: close header). urllib2 is indicating that some of the non-80 slowness is still being sent over an established connection. The mystery continues...
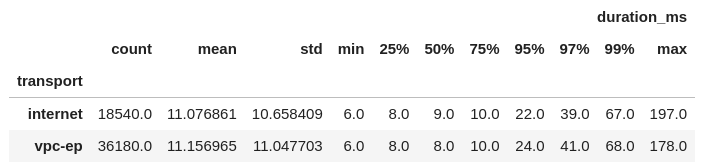
There was some question what kind of performance impact VPC Endpoints would have. So I set one up for SQS in my test VPC and the results were... meh. Here's a histogram of call times and some summary statistics:
Completely meh. The VPC Endpoints runs are actually worse at the tail. You'd think that eliminating any extra network hops through an Endpoint would reduce that, but 🤷.
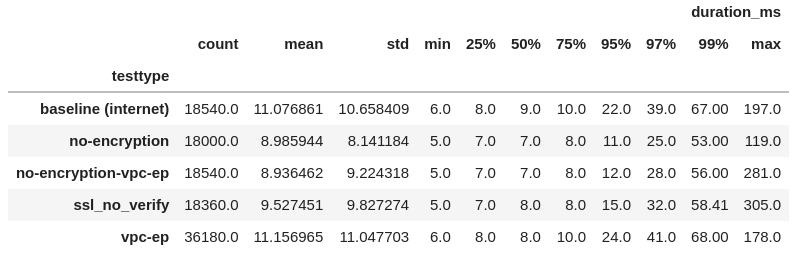
Here are all the test parameters I checked. You can see that the 99% remains pretty high.
I think this is the end of the line for SQS performance. We've made sure that everything between us and SQS is removed and yet we're still seeing random spikes of latency that can't be explained by connection reuse.
At my company, we use AWS Simple Queue Service (SQS)
for a lot of heavy lifting. We send ✨many✨ messages. I can say that
it's into the millions per day. Because we call SQS so frequently and instrument everything, we get
to see its varied performance under different conditions.
Our application backend is written in Python using Django and Gunicorn and uses the pre-fork model.1
This means that we always need to have a Gunicorn process available and waiting to pick up a connection
when it comes in. If no Gunicorn process is available to receive the connection, it just sits and hangs.
This means that we need to optimize on keeping Gunicorn processes free. One of the main ways to do this
is to minimize the amount of work a process must perform in order to satisfy any single API request.
But that work still needs to be done, after all.
So we have a bunch of separate workers waiting to receive tasks in the background.
These background workers process work that takes a long time to complete.
We offload all long work from our Gunicorn workers to our background workers.
But how do you get the work from your frontend Guncicorn processes to your background worker pool?
The answer is by using a message queue. Your frontend writes ("produces") jobs to the message queue.
The message queue saves it (so you don't lose work) and then manages the process of routing it to a background worker (the "consumers"). The message queue we use is SQS. We use the wonderful
celery project to manage the producer/consumer interface. But the performance characteristics all come from SQS.
To recap, if a Gunicorn API process needs to do any non-negligible amount of work when
handling a web request, it will create a
task to run in the background and send it to SQS
through the sqs:SendMessage AWS API.
The net effect is that the long work has been moved off the critical path and into the background.
The only work remaining on the critical path is the act of sending the task to the message queue.
So as long as you keep the task-send times low, everything is great. The problem is that sometimes
the task-send times are high. You pay the price for this on the critical path.
We care a lot about our API response time: high response times lead to
worse user experiences. Nobody wants to click a button in an app and get
three seconds of spinners before anything happens. That sucks. It's bad U/X.
One of the most valuable measures of performance in the real world is tail latency.
You might think of it as
how your app has performed in the worst cases. You line up all your response
times (fastest-to-slowest) and look at the worst offenders. This is very hard
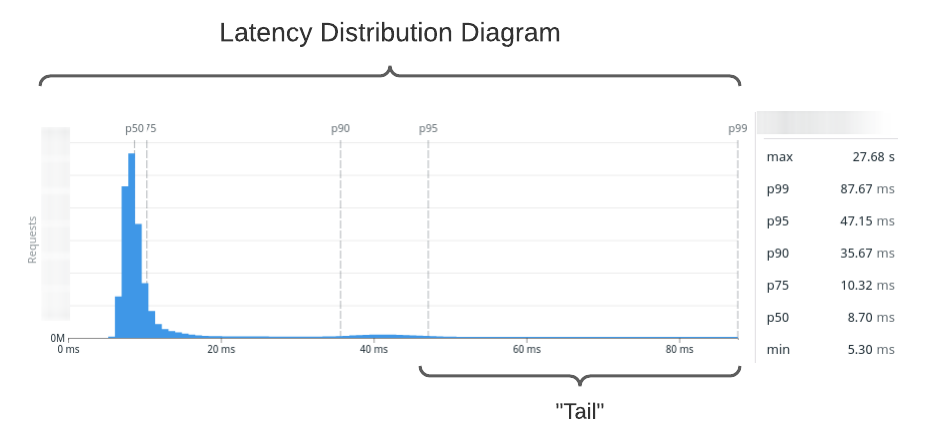
to visualize, so we apply one more transformation: we make a histogram.
We make response time buckets and count
each response time in the bucket. Now we've formed a latency distribution diagram.
Quick note for the uninitiated: pX are percentiles. Roughly, this means that pX is the Xth slowest
time out of 100 samples. For example, p95 is the 95th slowest. It scales, too:
p99.99 is the 9,999th slowest out of 10,000 samples.
If you're more in the world of statistics, you'll often see it written with
subscript such as p95.
You can use your latency distribution diagram to understand at a glance how your application
performs. Here's our sqs:SendMessage latency distribution sampled over the past month.
I've labeled the high-end of the distribution, which we call the tail.
We have a backend-wide
meeting twice a month where we go over each endpoint's performance. We generally
aim for responses in less than 100 milliseconds. Some APIs are inherently more expensive,
they will take longer, and that's ok. But the general target is 100ms.
One of the most useful tools for figuring out what's going on during a request is
(distributed) tracing! You may have heard of this under an older and more vague name: "application
performance monitoring" (APM). Our vendor of choice for this is
Datadog, who provides an excellent
tracing product.
For the last several performance meetings, we've had the same problem crop up. We look at the slowest
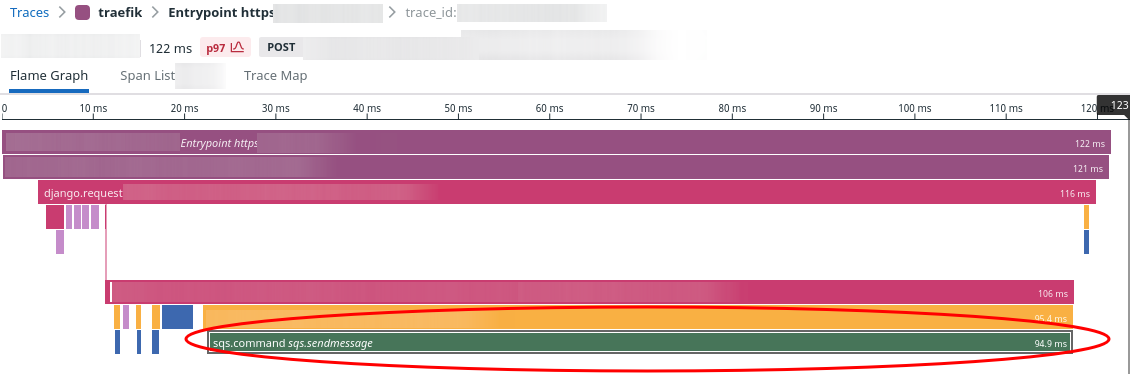
1-3% of calls for a given API endpoint and they always look the same. Here's a representative sample:
See the big green bar at the bottom? That is all sqs:SendMessage. Of the request's 122ms response time, 95ms or
75% of the total time was waiting for SQS:SendMessage. This specific sample was the p97 for this
API endpoint.
There are two insights we get from this trace:
To improve the performance of this endpoint, we need to focus on SQS. Nothing else really matters.
High tail latency for any of our service dependencies are going to directly drive our API performance at the tail.
Of course, this makes total sense. But it's good to acknowledge it explicitly!
It's futile to try to squeeze better performance out of your own service if a dependency
has poor tail latency.
The only way to improve the tail latency is to either drop the poor performer
or to change the semantics of your endpoint. A third option is to attempt to alleviate the tail latencies
for your service dependency if you can do so. You can do
this if you own the service! But sometimes, all you have is a black box owned by a third party (like SQS).
An example of changing API semantics: instead of performing the blocking SendMessage operation
on the main API handler thread, you might spin the call out to its own dedicated thread. Then, you might check
on the send status before the API request finishes.
The semantic "twist" happens when you consider what
happens in the case of a 5, 10, or even 20 second SendMessage call time. What does the API thread do when
it's done handling the API request but the SendMessage operation still hasn't yet been completed?
Do you just... skip waiting for the send to complete and move
on? If so, your semantics have changed: you can no longer guarantee that you durably saved the task.
Your task may never get run because it never got sent.
For some exceedingly rare endpoints, that's acceptable behavior. For most, it's not.
There is yet another point hidden in my example. Instead of just not caring whether the task was sent,
say instead we block the API response until the task send completes (off thread).
Basically, we get the amount of time we spend doing other non-SQS things shaved
off of the SQS time. But we still have to pay for everything over the other useful time.
In this case, we've only improved perhaps the p80-p95 of our endpoint.
But the worst-case p95+ will still stay the same! If our goal in making that change was to reduce the
p95+ latency then we would have failed.
SQS has a few knobs we can turn to see if they help with latency. Really, these knobs are other SQS features,
but perhaps we can find some correlation to what causes latency spikes and
work around them. Furthermore, we can use our knowledge of
the transport stack to make a few educated guesses.
Since SQS is a black box to us, this is very much spooky action at a distance.
How about initiating new connections to the SQS service before keep-alive kicks in on boto3. If our process has never
talked to SQS before, it stands to reason that there is some initial cost in establishing a connection to it in
terms of TCP setup, TLS handshaking, and perhaps some IAM controls on AWS' side.
To test this, we ran a test that cold-started an SQS connection, sent the first message, and then sent several
messages afterwards when keep-alive was active. Indeed, we found that
the p95 of the first SendMessage was 87ms and the p95 of the following 19 calls was 6ms.
It sure seems like cold-starts are the issue. Keep-alive should fix this issue.
A confounding variable is that sometimes we see slow SendMessage calls even in the next 20 operations following an
initial message. If the slow call was just the first call, we could probably work around it. But it's not
just the first one.
In boto, you can set the maximum amount of time that urllib will keep a connection around
without closing it. It should really only affect idle connections, however.
We cranked this up to 1 hour and there was no effect on send times.
Our queues are encrypted with AWS KMS keys. Perhaps this adds jitter?
Our testing found KMS queue encryption does not have an effect on SendMessage calls.
It did not matter if the data key reuse period was 1 minute or 12 hours.
Enabling encryption
increased the p95 of SendMessage by 6ms. From 12ms without encryption to 18ms with encryption.
That's pretty far away from the magic number of 100ms we are looking for.
Perhaps some infrastructure process happening behind the scenes when we scale up/down and send more (or fewer)
messages throughout the day. If so, we might see performance degradation when we are transitioning
along the edges of the scaling step function. Perhaps SQS is rebalancing partitions in the background.
If this were to be the case, then we would see high latency spikes sporadically
during certain periods throughout the day.
We'd see slow calls happen in bursts. I could not find any evidence of this from our metrics.
Instead, the slow calls are spread out throughout the day. No spikes.
Frankly, I consider this answer kind of a cop-out from AWS. For being a critical service to many
projects, the published performance numbers are too vague. I had a brief foray into hardware
last year. One of the best aspects of the hardware
space is that every component has a very detailed spec sheet. You get characteristic curves for all kinds
of conditions. In software, it's just a crapshoot. Services aiming to underpin your own service
should be publishing spec sheets.
Normally, finding out the designed performance characteristics are suboptimal would be the end of the road.
We'd start looking at other message queues. But we are tied to SQS right now.
We know that the p90 for SendMessage is 40ms so we know latencies lower than 100ms are possible.
We don't have a great solution to increase SQS performance. Our best lead is
cold-start connection times. But we have tweaked all the configuration that
is available to us and we still do not see improved tail latency.
If we want to improve our endpoint tail latency, we'll probably have to replace SQS
with another message queue.
Amazon recently announced the general availability of Athena 2, which contains a bunch of performance improvements and features.
As part of our release process, we query all of our Cloudtrail logs to ensure that no secrets were modified unexpectedly.
But Cloudtrail has hundreds of thousands of tiny JSON files, and querying them with Athena takes forever.
This is because under the hood Athena has to fetch each file from S3.
This takes 20-30 minutes to run, and hurts the developer experience.
Worse than taking forever, it frequently throws an error of Query exhausted resources at this scale factor.
The documentation suggests this is because our query uses more resources than planned. While you can typically
get this error to go away if you run the same query a few more times, you only encounter the error after 15 minutes.
It's a huge waste of time.
To fix this, every night we combine all tiny Cloudtrail files into a single large file.
This file is about 900 MB of raw data but compresses down to only 60 MB.
We instead build our Athena schema over these compressed daily Cloudtrail files and query them instead.
This reduces the query time to only 3-4 minutes or so.
This worked great on Athena 1. But on Athena 2, we started seeing errors like this:
Your query has the following error(s): HIVE_BAD_DATA: Line too long in text file: s3://xxx/rollup/dt=20190622/data.json.gz This query ran against the "default" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: aaa8d916-xxxx-yyyy-zzzz-000000000000.
Contrary to the error message, none of the lines in the file are too long. They are at most about 2kb.
There seems to be a bug in the AWS-provided Cloudtrail parser that treats the whole file as a single line which violates some hidden cap on line-length.
Some sleuthing of the Presto source code (which Athena is based on) shows that there is a default line length of 100 MB.
Now, we split the consolidated Cloudtrail log into 100 MB chunks and query those instead.
This works out fine. But it's a pain and a waste of time to do this.
Athena has a cap on the total number of partitions you can have in a table.
We used to consume only one partition per day, but this change ups it to 9 per day (and growing with data growth).
Since the cap is 20,000, we're still well within quota.
I'm hoping that AWS will fix this bug soon. Everything about it is needlessly annoying.
Our Django application connects to MySQL to store all of its data. This is a pretty typical setup. However, you may not know that establishing connections to MySQL is rather expensive.
I have written previously about controlling API response times -- we take it very seriously! One thing that blows up response latencies at higher percentiles is when our application has to establish a new MySQL connection. This tacks on an additional 30-60ms of response time. This cost comes from the MySQL server-side -- connections are internally expensive and require allocating buffers.
The network does not significantly contribute to the setup cost. Go ahead and set up a local MySQL server and take connection timings. You will still see 30ish milliseconds even over loopback! Even AWS' own connection guide for debugging MySQL packets shows the handshake taking 40ms!
We have two other wrinkles:
Django adds some preamble queries, so that adds further to connection setup costs.
We need to be able to gracefully (and quickly) recover from database failover. In practice, this means that we need to re-resolve the database hostname every time we connect. RDS DNS resolution is slow. I have the receipts! These instrumented numbers factor in cache hits.
All of this is to say that you want to reduce the number of times that you have to establish a MySQL connection.
The most straightforward way to do this is to reuse connections. And this actually works great up to a certain point. However, there are two quirks:
First, connections have server-side state that is expensive to maintain. A connection may take up a megabyte of ram on the database even if the connection is doing nothing. This number is highly sensitive to database configuration parameters. This cost is multiplied by thousands of connections.
Second, we have API processes and background processes that often times are doing nothing. Due to the nature of our workload, many of our services are busy and times when other services are not. In aggregate, we have a nice load pattern. But each particular service has a spiky load pattern. If we keep connections open forever, we are hogging database resources for connections that are not being used.
We have here a classic engineering tradeoff! Do we keep the connections open forever and hog database resources to ultimately minimize database connection attempts?
But we want low idle waste while also having minimal reconnects and a lower p95. What do we do?
The answer is to use a database proxy. Instead of your clients connecting directly to the database server, the clients makes a "frontend connection" to the proxy. The proxy then establishes a matching "backend connection" to the real database server. Proxies (generally) talk MySQL wire protocol, so as far as your application code is concerned nothing has changed.
When your client is longer actively using the MySQL connection, the proxy will mark the backend connection as inactive. Next time a client wants to connect to the database via the proxy, the proxy will simply reuse the existing MySQL connection instead of creating a new one.
Thus, two (or more) client MySQL connections can be multiplexed onto a single real backend connection. The effect of this is that
The number of connections to the MySQL database is cut down significantly, and
Clients connecting to the proxy are serviced very quickly. Clients don't have to wait for the slow backend connection setup.
The first wrinkle is that if both frontend connections want to talk to the database at the same time then the proxy has to either
Wait for one frontend connection to become inactive before servicing the other (introducing wait time), or
Spin up another backend connection so that both frontend connections can be serviced at the same time, which makes you still pay the connection setup price as well as the backend state price.
What the proxy actually does in this case depends on the configuration.
A second wrinkle occurs due to the highly-stateful nature of MySQL connections. There is a lot of backend state for a connection. The proxy needs to know about this state as well, or is it could errantly multiplex a frontend connection onto a backend connection where the expected states are misaligned. This is a fast way to get big issues.
To solve this, proxies track the state of each frontend and backend connection. When the proxy detects that a connection has done something to affect the state that tightly bounds the frontend to the backend connection, the proxy will "pin" the frontend to the backend and prevent backend reuse.
There are a few MySQL database proxies that are big in the FOSS ecosystem right now. The top two are sqlproxy (which is relatively new),
and Vitess (where the proxy ability is just small part in a much larger project). Running a proxy yourself is adding more custom infrastructure that
comes with its own headaches though. A managed/vendor-hosted version is better at our scale.
And, what do you know? AWS just released RDS Proxy with support for Aurora MySQL. I tried it out and found it... wanting.
Look for my experience with RDS proxy in a post coming soon!
A few months ago AWS introduced a new service called Global Accelerator.
AWS Cloudfront PoPs around the United States.
This service is designed to accept traffic at local edge locations (maybe the same Cloudfront PoPs?) and then route it
over the AWS backbone to your service region.
An interesting feature is that it does edge TCP termination, which can save latency on quite a few packet round trips.
Bear in mind, that after the TCP handshake, the TLS handshake is still required and that requires a round trip to the
us-west-2 (Oregon) region regardless of the edge location used by Global Accelerator.
Of course I am a sucker for these "free" latency improvements, so I decided to give it a try and set it up
on our staging environment. I asked a few coworkers around the United States to run some tests and here are the savings:
Location
TCP Shake
TLS Handshake
Weighted Savings
Hunter @ San Francisco
-42 ms
-1 ms
-43 ms
Kevin @ Iowa
-63 ms
-43 ms
-131 ms
Matt @ Kentucky
-58 ms
-27 ms
-98 ms
Sajid @ Texas
-50 ms
+57 ms
-14 ms
My own entry from San Francisco makes total sense. We see a savings on the time to set up the TCP connection because
instead of having to roundtrip to Oregon, the connection can be set up in San Jose.
It also makes sense that the TLS Handshake did not see any savings, as that still has to go to Oregon. The
path from SF Bay Area to Oregon is pretty good, so there is not a lot of savings to be had there.
However, for Iowa and Kentucky, the savings are quite significant. This is because instead of transiting
over the public internet, the traffic is now going over the AWS backbone.
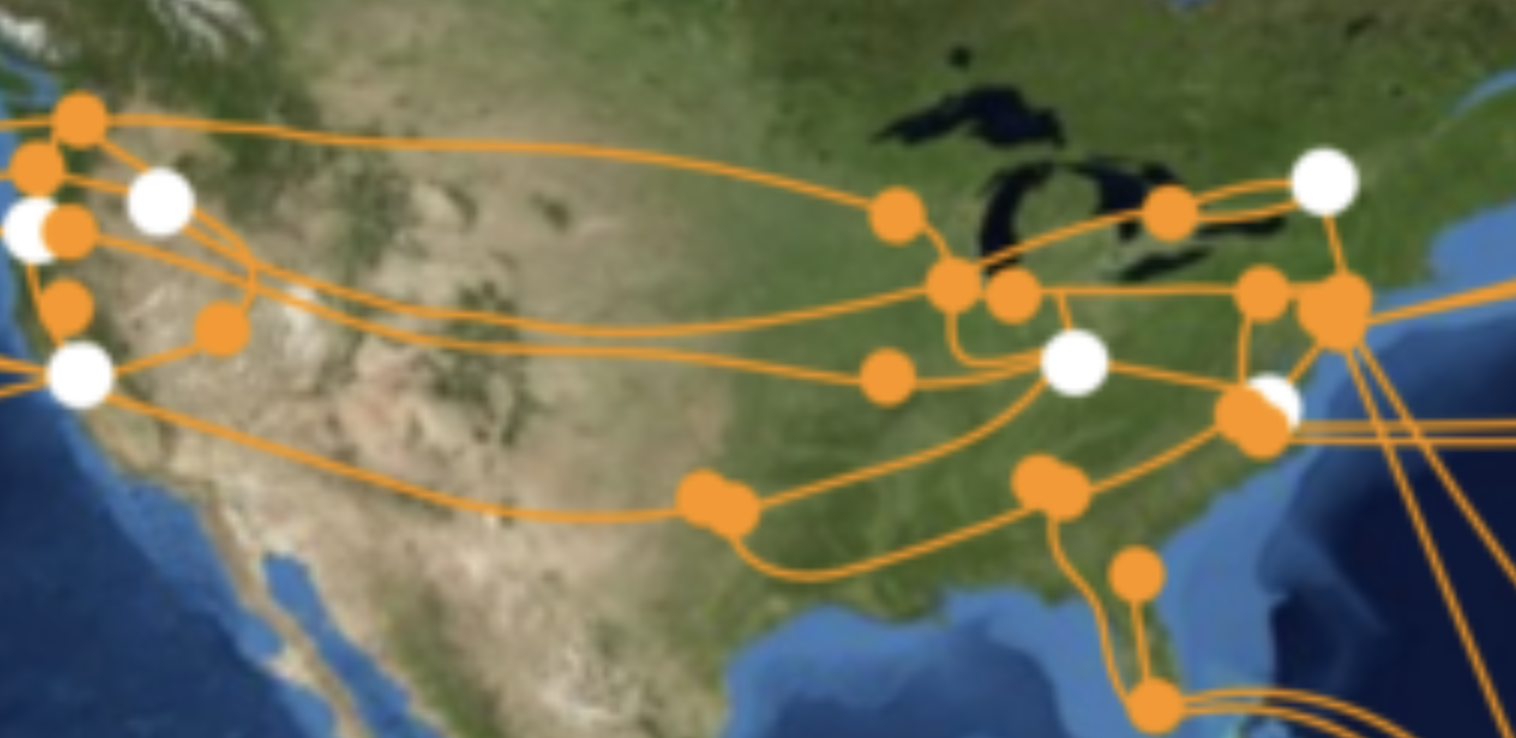
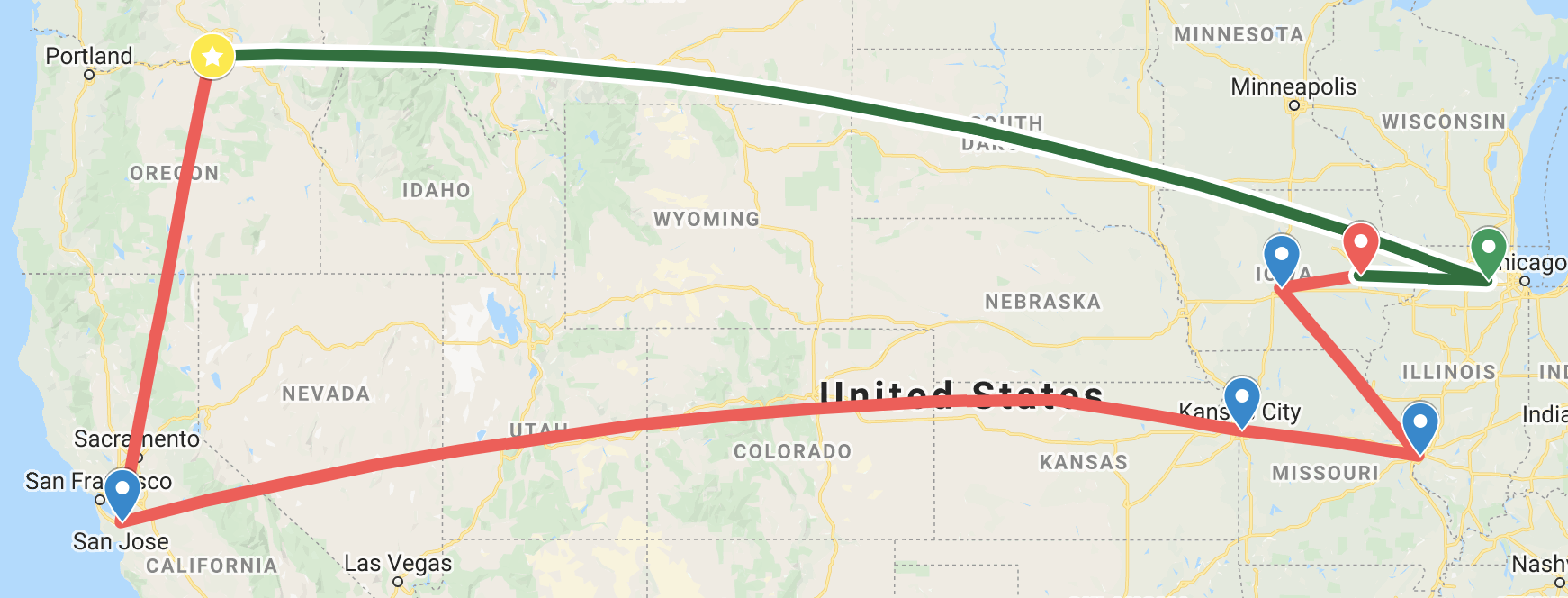
Here's a traceroute from Iowa comparing the public internet to using Global Accelerator.
Green is with Global Accelerator.
Red is without Global Accelerator using the public internet.
You can see that the path is much shorter and more direct with Global Accelerator. Honestly, me using Iowa
as a comparison here is a bit of a cheat, as you can see from the AWS PoP / Backbone map that there is a
direct line from Iowa to Oregon.
But that is kind of the point?
AWS is incentivized for performance reasons to create PoPs in places with lots of people.
AWS is incentivized to build our their backbone to their own PoPs.
Our customers are likely to be in placed with lots of people.
Therefore Global Accelerator lets us reach our customers more directly and AWS is incentivized
keep building that network out.
Where it gets weird is Texas. The TCP handshake is faster, but the TLS handshake is slower. I am not sure why this is.
In fact, I checked with other coworkers from different areas in Texas and they had better results.
I was happy with the results and decided to roll it out to production while keeping an eye on the metrics from Texas.
We rolled it out to 5% of our traffic and everything seemed to be going well, so we rolled it out to 20% then 100% of our traffic.
We observed a 17% reduction in latency across the board and a 38% reduction in the 99th percentile latency.
That is an amazing improvement for a service that is just a few clicks to set up.
I am pleased to say the data from Texas has improved as well.
While I am not sure what the issue was, it seems to have resolved itself.
Hopefully AWS will release some better network observation tools in the future to aid debugging these issues.
Our continuous integration provider is CircleCI -- we love them!
Every time an engineer merges code, several builds get kicked off. Among these is a
comprehensive suite of end-to-end tests that run against a shadow cluster.
We call this shadow-cluster testing environment simply "CICD" (Continuous Integration/Continuous Deployment;
we're bad at naming).
Its primary purpose in life is to fail when problematic code gets released.
CICD dies early so that prod doesn't later on. There are other niceties from having it, but
lighting on fire before prod is one of the more valuable aspects.
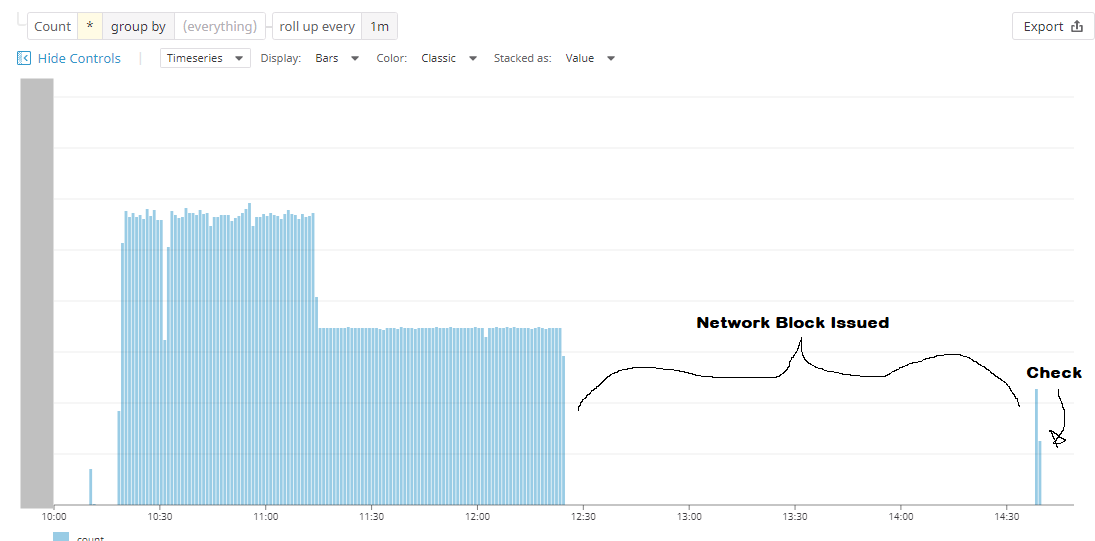
One day a few weeks ago, alerts started firing and our CICD site was slow. Ouch. What gives?
It seems that CircleCI was repeatedly running a test exercising
an especially expensive API. Normally, we'd
expect this endpoint to be called in short, small bursts. Now, however, it was being
called constantly from a single IP address.
Side note: you really should not be doing a large amount of work
while handling a request. Doing so exposes yourself to denial-of-service vectors.
CircleCI was very responsive and confirmed that one of their machines had entered
an error state. As it turns out, the expensive job was one of the first tasks
executed by a worker shard (before the task was promptly killed and run again, ad nauseam).
To immediately restore service to the rest of our engineering team,
we black-holed traffic from this IP address
via AWS Network Access Control List rules.
This incident, while manageable and only affecting our CICD environment,
led us to consider how to block problematic requests in the future.
We have a few interrelated goals for our rate limiting:
Prevent a single entity from DOSing our API. We are explicitly not attempting to counter
a coordinated malicious user with rate limiting. A sufficiently-motivated attacker
could use many thousands of IP addresses. For complex attacks, we have tools like AWS WAF.
It's more of a sledgehammer when we're looking for a scalpel. But when under attack, we can
flip WAF on.
Enforce baseline usage. Rate limiting gives us another gauge and lever of control
over our client software. My firm belief about software is that, if left unchecked, it grows unruly and
underpeformant naturally. It's just a fact of life. (Maybe I am showing my ops colors here).
In order to keep the system snappy for each user, it's
important to limit the calling capacity of all users and force clients to use
best-practices. That means, for example, calling batch APIs instead of single-APIs individually one by one.
Within reason, of course. We know ahead of time that in the future, we'll need to tweak limit thresholds as
our product grows in features and scope. Here, limitations lead to better individual client
performance. We don't want to put the cart before the horse.
Minimal amount of processing for rejected requests. If
we reject requests because they are over the rate limit threshold,
we want to spend as few resources processing the reject as possible. It's a throw-away request,
after all. Minimizing processing greatly influences where we want to enforce the rate limit
in our request-response infrastructure.
Rate limiting the user, not the IP address. A significant number of our customers are large
health systems. We see many healthcare providers (who use our most computationally-expensive features)
connecting from the same IP address. They tend to all be behind a proxy appliance such as
Blue Coat "for compliance reasons."
Side note: these insane proxies/man-in-the-middle boxes like Blue Coat are one of the reasons
I don't think websites/app backends should participate in
HTTP public key pinning.
There are many other reasons, but this is the first that most backend folks will run into.
We don't want to give large hospitals the same limit as we would give to a single user.
Therefore, we want
to preferentially rate limit based on authenticated user ID. But, if the client is not logged in and
all we have is the IP address, then we'll have to rate limit on that. Still, we'd prefer the
authenticated user ID!
We considered four locations to enforce a rate limit. We strongly considered
changing fundamental parts of our infrastructure to prevent malicious attacks
like this in the future.
The candidates were:
A Cloudfront global rate limit.
An API Gateway rate limit.
A Traefik plugin to implement rate limiting.
Adding rate limiting as Django Middleware.
While Cloudfront offered us the chance of caching certain content (and killing
two birds with one stone), we ruled it out because there are technical issues
ensuring that clients cannot connect directly to our backend instead
of solely through CF. The solution
would involve custom header values and... it's all around very hacky.
We ruled API Gateway out because we did not want to restrict ourselves to the
10MB POST payload size limitation. We accept CCDAs and process
them. They can get very large -- sometimes over a hundred MB.
In the future, we'll move this to direct client-to-S3 uploads, but that is out of the scope
of this post.
Traefik has a built-in rate limiting mechanism, but it only works on IP
addresses and we have the requirement to throttle based on user ID if it's available.
Hopefully, Traefik will add support for custom plugins soon. They've slated it for Traefik 2.
So we are left with implementing our own logic in Django Middleware. This is the worst
option in one important way: the client connection has to make it all the way into
our Gunicorn process before we can accept/reject the request for being over quota. Ouch.
We really want to protect the Gunicorn processes as much as possible. We can handle as many requests
in parallel as we have Gunicorn processes. If a process is stuck doing rate limiting,
it won't be processing another request. If many requests are coming in from a client
who is spamming us, we don't want all of our Gunicorn processes
dealing with those. This is an important DOS vector.
Unfortunately for us, Django Middleware is the best we're going to be able to do for now.
So that's where we're going to put our code!
There are many, many algorithms for rate limiting. There's leaky bucket, token bucket, and sliding
window, to name a few.
We want simplicity for our clients. Ideally, our clients should not have to think about rate
limiting or slowing down their code to a certain point. For one-off script runs, we'd like just
to accept the load. We want programming against our API to be as simple as possible for our
customers. The net effect of this is that we're looking for an algorithm that gives us
high burst capacity. Yes, this means the load is spikier and compressible into a narrower
timeframe, but the simplicity is worth it
After considering our options, we went with the fixed-window rate limiting algorithm.
The way fixed-widow works is that you break time up into... uh... fixed windows. For us,
we chose 5 minute periods. For example, a period starts at the top of the hour and ends 5 minutes into the hour.
Then, for every request that happens in that period, we increment a counter. If the counter is over
our rate limit threshold, we reject the request.
A drawback of the fixed window algorithm is that the user can spend about 2x the limit.
And they can spend 2x as fast as they want
if they do it at the period boundary.
You could offset boundaries based on user ID/IP hashes to amortize
this risk... but I think it's too low to consider at this time.
This "shared counter" idea maps nicely to our "microservices with a shared Redis cache" architecture.
Implementing the algorithm is simple! At the start of each request, we run a single command against Redis:
INCR ratelimit/{userid|ip}/2019-01-01_1220
Redis, as an entirely in-memory store, does this super fast. The network latency within an availability zone
is several orders of magnitude more than the time it takes Redis to parse this statement and increment
this integer. This is highly scalable and is an extremely low-cost to perform rate limiting.
We can even shard on user-id/IP when it comes time to scale out.
INCR returns the now-incremented number, and our code verifies this is below the rate limit threshold. If it's
above the limit, we reject the request.
There are key expiration considerations:
The effect of this happening in the short term to an active key
for an active period would be the user getting more
requests then we'd usually give them. Whatever. That's acceptable for us. We're not
billing per-request. We don't need to ensure that we have a perfectly accurate count.
In the long term, the key will stick around indefinitely until it's evicted
at Redis' leasure (when Redis needs to reclaim memory).
We don't have a durability requirement and, in fact, we want it to go away after we're done with it.
So INCR by itself is a fine solution. However, you can also pipeline an EXPIREAT if you want to guarantee that the key is removed after the period has expired.
To choose our specific rate limit threshold, we scanned a month's worth of logs. We applied
different theoretically thresholds to see how many requests and users we'd affect.
We want to find a threshold where we affected a sufficiently low:
Number of unique users.
Number of unique user-periods.
These are different. For example, consider the following:
If we had 100 users in a month with 99 of them behaving well and sparsely calling us thrice a day
while
the last user constantly hammered us, we'd calculate that 1% of users affected and
97% of user-periods affected. Threshold-violating users inherently generate more
user-periods than normal users.
So our guiding metric is the number of unique users affected. We'll also pay attention to the number
of affected user-periods, but only as supplementary information.
We ended up choosing a threshold that affects less than 0.1% (p99.9) of users and less than
0.01% (p99.99) of user-periods. It sits at approximately three times our peak usage.
While our clients should not have to fret about the rate limit, the software we write still needs to be aware that it exists. Errors happen. Our software needs to know how to handle them.
Therefore, in every API response, we return the following API headers to inform
the client of their rate limiting quota usage:
X-Ratelimit-Limit -- The maximum number of requests that the client can perform in a period. This is customizable per user.
X-Ratelimit-Used -- How many requests the client has consumed.
X-Ratelimit-Remaining -- How many more requests the client can perform in the current period.
X-Ratelimit-Reset -- The time in UTC that the next period resets. Really, this is just when the next
period starts.
Additionally, when we reject a request for being over the rate limiting threshold, we return
HTTP 429 Too Many Requests.
This makes the error handling logic very simple:
if response.status_code ==429: reset_time =int(response['X-Ratelimit-Reset']) time.sleep(max(reset_time - now(),0)) retry()
And of course, I always include operations dials that can be turned and
escape hatches that we can climb through in an emergency. We also added:
The ability to modify the global threshold at runtime (or disable it entirely) without
requiring a process restart. We stick global configuration into Redis for clients to
periodically refresh. On the side, we update this from a more durable source of truth.
We allow custom quotas per user by optionally attaching a quota claim to the user JWT.
Note that this doesn't work for IP addresses. It's conceivable that we may add a secondary
Redis lookup for per-IP custom quotas. We could also pipeline this operation into our
initial Redis INCR and so it would add very little overhead.
We continuously validate our quota threshold.
We have added a stage to our logging pipeline to gather the MAX(Used) quota over periods.
Our target is to ensure that the p99.9 of users are within our default quota.
We compute this every day over a 30-day rolling window and pipe this into Datadog.
We alert if the number is significantly different from our expectation.
This prevents our actual usage of the API from drifting close to our quota limit.
Eventually, we'd like to move this into our reverse proxy (Traefik).
While Traefik does buffer the headers and body (so we are not exposed to slow
client writes/reads) it would be best if
our Python application does not need to handle this connection at all.


-f21ebb7a387e4abe81a9b92aba76a8ed.png)
-5111147b6c1dc040d8ef97a2366a70df.png)

-7cd5d20668ae8d5a47e657200d89ab0f.png)